Teknik Industri
Kebersihan di Tempat Kerja
Dipublikasikan oleh Anjas Mifta Huda pada 10 Februari 2025
Nada atau gaya artikel ini mungkin tidak mencerminkan nada ensiklopedis yang digunakan di Wikipedia. Lihat panduan menulis artikel yang lebih baik di Wikipedia untuk mendapatkan saran. (Januari 2024) (Pelajari bagaimana dan kapan menghapus pesan ini)
Ilustrasi Penilaian dan Manajemen Risiko Pajanan yang terkait dengan antisipasi, pengenalan, evaluasi, pengendalian, dan konfirmasi
Higiene kerja (Amerika Serikat: industrial hygiene (IH)) adalah antisipasi, pengenalan, evaluasi, pengendalian, dan konfirmasi (ARECC) perlindungan dari risiko yang terkait dengan pajanan bahaya di, atau yang timbul dari, tempat kerja yang dapat mengakibatkan cedera, penyakit, gangguan, atau memengaruhi kesejahteraan pekerja dan anggota masyarakat. Bahaya atau pemicu stres ini biasanya dibagi ke dalam kategori biologis, kimiawi, fisik, ergonomis, dan psikososial.
- Risiko dampak kesehatan dari pemicu stres tertentu adalah fungsi dari bahaya yang dikalikan dengan paparan individu atau kelompok.
- Untuk bahan kimiawi, bahayanya dapat dipahami melalui profil respons dosis yang paling sering didasarkan pada studi atau model toksikologi. Ahli higiene lingkungan bekerja sama dengan ahli toksikologi (lihat Toksikologi) untuk memahami bahaya kimia, fisikawan (lihat Fisika) untuk bahaya fisik, dan dokter serta ahli mikrobiologi untuk bahaya biologis (lihat Mikrobiologi Infeksi obat tropis). Ahli higiene lingkungan dan pekerjaan dianggap sebagai ahli dalam ilmu pengetahuan tentang pajanan dan manajemen risiko pajanan.
Tergantung pada jenis pekerjaan seseorang, ahli higiene akan menerapkan keahlian ilmu pajanan mereka untuk melindungi pekerja, konsumen, dan/atau masyarakat.
Profesi ahli higiene kerja
British Occupational Hygiene Society (BOHS) mendefinisikan bahwa “higiene kerja adalah tentang pencegahan penyakit akibat kerja, dengan cara mengenali, mengevaluasi, dan mengendalikan risikonya. Asosiasi Higiene Kerja Internasional (IOHA) mengacu pada higiene kerja sebagai disiplin ilmu yang mengantisipasi, mengenali, mengevaluasi, dan mengendalikan bahaya kesehatan di lingkungan kerja dengan tujuan untuk melindungi kesehatan dan kesejahteraan pekerja serta melindungi masyarakat pada umumnya.
Istilah “higiene kerja” (digunakan di Inggris dan negara-negara Persemakmuran serta sebagian besar Eropa) identik dengan higiene industri (digunakan di AS, Amerika Latin, dan negara-negara lain yang menerima dukungan teknis awal atau pelatihan dari sumber-sumber AS). Istilah “higiene industri” secara tradisional berasal dari industri konstruksi, pertambangan atau manufaktur, dan “higiene kerja” mengacu pada semua jenis industri seperti yang tercantum untuk “higiene industri” serta industri jasa keuangan dan jasa pendukung dan mengacu pada “pekerjaan”, “tempat kerja” dan “tempat kerja” secara umum.
Higiene lingkungan membahas isu-isu yang serupa dengan higiene kerja tetapi cenderung tentang industri yang luas atau isu-isu yang luas yang mempengaruhi masyarakat lokal, masyarakat yang lebih luas, wilayah atau negara.
Profesi higiene kerja menggunakan metodologi ilmiah yang ketat dan ketat dan sering kali membutuhkan penilaian profesional berdasarkan pengalaman dan pendidikan dalam menentukan potensi risiko paparan berbahaya di tempat kerja dan studi lingkungan. Aspek-aspek higiene kerja ini sering disebut sebagai “seni” higiene kerja dan digunakan dalam pengertian yang sama dengan “seni” kedokteran. Faktanya, “higiene kerja” merupakan aspek dari kedokteran pencegahan dan khususnya kedokteran kerja, karena tujuannya adalah untuk mencegah penyakit industri, dengan menggunakan ilmu manajemen risiko, penilaian paparan, dan keselamatan industri.
Pada akhirnya, para profesional berusaha menerapkan sistem, prosedur atau metode yang “aman” untuk diterapkan di tempat kerja atau lingkungan. Pencegahan paparan jam kerja yang panjang telah diidentifikasi sebagai fokus untuk higiene kerja ketika sebuah studi penting Perserikatan Bangsa-Bangsa memperkirakan bahwa bahaya pekerjaan ini menyebabkan sekitar 745.000 kematian akibat kerja per tahun di seluruh dunia, beban penyakit terbesar yang dikaitkan dengan bahaya pekerjaan tunggal.
Higiene Industri mengacu pada ilmu untuk mengantisipasi, mengenali, mengevaluasi, dan mengendalikan tempat kerja untuk mencegah penyakit atau cedera pada pekerja (Geigle Safety Group, Inc., 2020). Ahli higiene industri menggunakan berbagai metode pemantauan dan analisis lingkungan untuk menentukan bagaimana pekerja terpapar.
Selanjutnya, mereka menggunakan teknik seperti teknik dan kontrol praktik kerja untuk mengendalikan potensi bahaya kesehatan. Antisipasi melibatkan identifikasi potensi bahaya di tempat kerja sebelum bahaya tersebut muncul. Ketidakpastian bahaya kesehatan berkisar dari ekspektasi yang masuk akal hingga spekulasi belaka. Namun, hal ini menyiratkan bahwa ahli higiene industri harus memahami sifat perubahan dalam proses, produk, lingkungan, dan tenaga kerja di tempat kerja dan bagaimana hal tersebut dapat mempengaruhi kesejahteraan pekerja.
Pengenalan teknik, praktik kerja, dan kontrol administratif adalah cara utama untuk mengurangi paparan pekerja terhadap bahaya kerja. Pengenalan bahaya secara tepat waktu dapat meminimalkan paparan pekerja terhadap bahaya dengan menghilangkan atau mengurangi sumber bahaya atau mengisolasi pekerja dari bahaya.
Evaluasi tempat kerja merupakan langkah penting yang membantu ahli higiene industri untuk menentukan pekerjaan dan tempat kerja yang berpotensi menimbulkan masalah. Selama evaluasi, ahli higiene industri mengukur dan mengidentifikasi tugas-tugas yang bermasalah, paparan, dan tugas-tugas. Penilaian tempat kerja yang paling efektif mencakup semua pekerjaan, aktivitas kerja, dan operasi. Ahli higiene industri memeriksa penelitian dan evaluasi tentang bagaimana bahaya fisik atau kimiawi yang ada mempengaruhi kesehatan pekerja.
Jika tempat kerja mengandung bahaya kesehatan, ahli higiene industri merekomendasikan tindakan perbaikan yang tepat. Langkah-langkah pengendalian termasuk membuang bahan kimia beracun dan mengganti bahan beracun berbahaya dengan bahan yang tidak terlalu berbahaya. Hal ini juga mencakup membatasi operasi kerja atau menutup proses kerja dan memasang sistem ventilasi umum dan lokal. Pengendalian mengubah cara pelaksanaan tugas.
Beberapa kontrol praktik kerja dasar meliputi: mengikuti prosedur yang ditetapkan untuk mengurangi paparan saat berada di tempat kerja, memeriksa dan memelihara proses secara teratur, dan menerapkan prosedur tempat kerja yang wajar.
Higiene industri di Amerika Serikat mulai terbentuk pada awal abad ke-20. Sebelumnya, banyak pekerja yang mempertaruhkan nyawa mereka setiap hari untuk bekerja di lingkungan industri seperti manufaktur, pabrik, konstruksi, dan tambang.
Saat ini, statistik keselamatan kerja biasanya diukur dengan jumlah cedera dan kematian setiap tahunnya. Sebelum abad ke-20, statistik semacam ini sulit didapat karena tampaknya tidak ada yang cukup peduli untuk menjadikan pelacakan cedera dan kematian akibat kerja sebagai prioritas. Profesi higiene industri mulai dikenal pada tahun 1700 ketika Bernardino Ramazzini menerbitkan sebuah buku yang komprehensif tentang kedokteran industri.
Buku ini ditulis dalam bahasa Italia dan dikenal sebagai De Morbis Artificum Diatriba, yang berarti “Penyakit Pekerja” (Geigle Safety Group, Inc., 2020).
Buku ini merinci deskripsi akurat tentang penyakit akibat kerja yang diderita oleh sebagian besar pekerja pada masanya. Ramazzini sangat penting bagi masa depan profesi higiene industri karena ia menegaskan bahwa penyakit akibat kerja harus dipelajari di lingkungan tempat kerja dan bukan di bangsal rumah sakit.
Higiene industri menerima dorongan lain pada awal abad ke-20 ketika Dr. Alice Hamilton memimpin upaya untuk meningkatkan higiene industri. Dia memulai dengan mengamati kondisi industri terlebih dahulu dan kemudian mengejutkan pemilik tambang, manajer pabrik, dan pejabat negara lainnya dengan bukti bahwa ada korelasi antara penyakit pekerja dan paparan mereka terhadap racun kimia. Dia mengajukan proposal definitif untuk menghilangkan kondisi kerja yang tidak sehat. Sebagai hasilnya, pemerintah federal AS juga mulai menyelidiki kondisi kesehatan di industri tersebut. Pada tahun 1911, negara bagian mengesahkan undang-undang kompensasi pekerja yang pertama.
Peran sosial dari higiene kerja
Ahli higiene kerja secara historis telah terlibat dalam mengubah persepsi masyarakat tentang sifat dan tingkat bahaya serta mencegah paparan di tempat kerja dan masyarakat. Banyak ahli higiene kerja yang bekerja sehari-hari dengan situasi industri yang membutuhkan pengendalian atau perbaikan situasi tempat kerja.
Namun, masalah sosial yang lebih besar yang mempengaruhi seluruh industri telah terjadi di masa lalu, misalnya sejak tahun 1900, paparan asbes yang telah mempengaruhi kehidupan puluhan ribu orang. Ahli higiene kerja telah menjadi lebih terlibat dalam memahami dan mengelola risiko paparan terhadap konsumen dari produk dengan peraturan seperti REACh (Registrasi, Evaluasi, Otorisasi, dan Pembatasan Bahan Kimia) yang diberlakukan pada tahun 2006.
Masalah yang lebih baru yang mempengaruhi masyarakat luas adalah, misalnya pada tahun 1976, penyakit Legiuner atau legionellosis. Baru-baru ini lagi pada tahun 1990-an, radon, dan pada tahun 2000-an, efek jamur dari situasi kualitas udara dalam ruangan di rumah dan di tempat kerja. Pada akhir tahun 2000-an, muncul kekhawatiran tentang efek kesehatan dari nanopartikel.
Banyak dari masalah ini membutuhkan koordinasi tenaga medis dan paraprofesional dalam mendeteksi dan kemudian mengkarakterisasi sifat dari masalah tersebut, baik dari segi bahaya maupun dari segi risiko terhadap tempat kerja dan pada akhirnya terhadap masyarakat. Hal ini melibatkan ahli higiene kerja dalam penelitian, pengumpulan data, dan pengembangan metodologi pengendalian yang sesuai dan memuaskan.
Kegiatan umum
Ahli higiene kerja dapat terlibat dalam penilaian dan pengendalian bahaya fisik, kimia, biologi atau lingkungan di tempat kerja atau masyarakat yang dapat menyebabkan cedera atau penyakit. Bahaya fisik dapat mencakup kebisingan, suhu yang ekstrem, pencahayaan yang ekstrem, radiasi pengion atau non-pengion, dan ergonomi. Bahaya kimiawi yang terkait dengan barang berbahaya atau zat berbahaya sering kali diselidiki oleh ahli higiene kerja.
Area terkait lainnya termasuk kualitas udara dalam ruangan (IAQ) dan keselamatan juga dapat menerima perhatian ahli higiene kerja. Bahaya biologis dapat berasal dari potensi paparan legionella di tempat kerja atau investigasi cedera biologis atau efek di tempat kerja, seperti dermatitis dapat diselidiki.
Sebagai bagian dari proses investigasi, ahli higiene kerja dapat diminta untuk berkomunikasi secara efektif mengenai sifat bahaya, potensi risiko, dan metode pengendalian yang tepat. Pengendalian yang tepat dipilih dari hirarki pengendalian: dengan eliminasi, substitusi, rekayasa, administrasi, dan alat pelindung diri (APD) untuk mengendalikan bahaya atau menghilangkan risiko.
Pengendalian tersebut dapat melibatkan rekomendasi sesederhana APD yang sesuai seperti masker debu partikulat 'dasar' hingga sesekali merancang sistem ventilasi ekstraksi debu, tempat kerja atau sistem manajemen untuk mengelola orang dan program untuk menjaga kesehatan dan kesejahteraan mereka yang masuk ke tempat kerja.
Contoh-contoh kebersihan kerja meliputi:
- Penyumbat telinga busa sekali pakai: keluar dari telinga dengan koin untuk skala (atas) dan dimasukkan ke dalam telinga pemakainya (bawah).
- Analisis bahaya fisik seperti kebisingan, yang mungkin memerlukan penggunaan penyumbat telinga dan/atau penutup telinga pelindung pendengaran untuk mencegah gangguan pendengaran.
- Mengembangkan rencana dan prosedur untuk melindungi dari paparan penyakit menular jika terjadi pandemi flu.
- Memantau udara dari kontaminan berbahaya yang berpotensi menyebabkan penyakit atau kematian pekerja.
Metode penilaian tempat kerja
Meskipun ada banyak aspek dalam pekerjaan higiene kerja, namun yang paling banyak diketahui dan dicari adalah dalam menentukan atau memperkirakan potensi atau paparan bahaya yang sebenarnya.
Untuk banyak bahan kimia dan bahaya fisik, batas paparan di tempat kerja telah diturunkan dengan menggunakan data toksikologi, epidemiologi, dan medis yang memungkinkan ahli higiene untuk mengurangi risiko dampak kesehatan dengan menerapkan “Hirarki Pengendalian Bahaya”. Beberapa metode dapat diterapkan dalam menilai tempat kerja atau lingkungan untuk mengetahui adanya paparan bahaya yang diketahui atau dicurigai. Ahli higiene kerja tidak bergantung pada keakuratan peralatan atau metode yang digunakan, tetapi dalam mengetahui dengan pasti dan tepat batas-batas peralatan atau metode yang digunakan dan kesalahan atau varians yang diberikan dengan menggunakan peralatan atau metode tertentu.
Metode-metode yang terkenal untuk melakukan penilaian paparan kerja dapat ditemukan dalam “Strategi untuk Menilai dan Mengelola Paparan Kerja.
Langkah-langkah utama yang diuraikan untuk menilai dan mengelola paparan kerja:
- Karakterisasi dasar (mengidentifikasi agen, bahaya, orang yang berpotensi terpapar, dan kontrol paparan yang ada)
- Penilaian pemaparan (pilih batas pemaparan di tempat kerja, pita bahaya, data toksikologi yang relevan untuk menentukan apakah pemaparan “dapat diterima”, “tidak dapat diterima”, atau “tidak pasti”)
- Kontrol pemaparan (untuk pemaparan yang “tidak dapat diterima” atau “tidak pasti”)
- Pengumpulan informasi lebih lanjut (untuk paparan yang “tidak pasti”)
- Komunikasi bahaya (untuk semua paparan)
- Penilaian ulang (sesuai kebutuhan)/Manajemen Perubahan
- Hirarki batas paparan kerja (OEL)
Karakterisasi dasar, identifikasi bahaya, dan survei langsung

Sumber: en.wikipedia.org
Langkah pertama dalam memahami risiko kesehatan yang terkait dengan paparan memerlukan pengumpulan informasi “karakterisasi dasar” dari sumber-sumber yang tersedia. Metode tradisional yang diterapkan oleh ahli higiene kerja untuk survei awal di tempat kerja atau lingkungan digunakan untuk menentukan jenis dan kemungkinan paparan bahaya (misalnya kebisingan, bahan kimia, radiasi).
Survei ini dapat ditargetkan atau dibatasi pada bahaya tertentu seperti debu silika, atau kebisingan, untuk memusatkan perhatian pada pengendalian semua bahaya bagi pekerja. Survei menyeluruh sering kali digunakan untuk memberikan informasi dalam menetapkan kerangka kerja untuk investigasi di masa depan, memprioritaskan bahaya, menentukan persyaratan untuk pengukuran dan menetapkan beberapa pengendalian langsung terhadap potensi paparan. Program Evaluasi Bahaya Kesehatan dari Institut Nasional untuk Keselamatan dan Kesehatan Kerja adalah contoh dari survei langsung higiene industri.
Sumber informasi karakterisasi dasar lainnya termasuk wawancara pekerja, mengamati tugas-tugas pemaparan, lembar data keselamatan bahan, penjadwalan tenaga kerja, data produksi, peralatan dan jadwal perawatan untuk mengidentifikasi agen pemaparan potensial dan orang-orang yang mungkin terpapar.
Informasi yang perlu dikumpulkan dari sumber-sumber tersebut harus sesuai dengan jenis pekerjaan tertentu yang menjadi sumber bahaya. Seperti yang telah disebutkan sebelumnya, contoh sumber-sumber ini termasuk wawancara dengan orang-orang yang pernah bekerja di bidang bahaya tersebut, sejarah dan analisis insiden di masa lalu, dan laporan resmi tentang pekerjaan dan bahaya yang dihadapi.
Dari semua itu, wawancara personil mungkin merupakan yang paling penting dalam mengidentifikasi praktik-praktik yang tidak terdokumentasi, kejadian, pelepasan, bahaya dan informasi lain yang relevan. Setelah informasi dikumpulkan dari berbagai sumber, sebaiknya informasi tersebut diarsipkan secara digital (untuk memudahkan pencarian cepat) dan memiliki kumpulan fisik dari informasi yang sama agar lebih mudah diakses.
Salah satu cara inovatif untuk menampilkan informasi bahaya historis yang kompleks adalah dengan peta identifikasi bahaya historis, yang menyaring informasi bahaya ke dalam format grafis yang mudah digunakan.
Pengambilan sampel

Sumber: en.wikipedia.org
Pengukuran tingkat kebisingan menggunakan pengukur tingkat kebisingan adalah komponen dari penilaian higiene kerja.
Ahli higiene kerja dapat menggunakan satu atau beberapa alat pengukur elektronik yang tersedia secara komersial untuk mengukur kebisingan, getaran, radiasi pengion dan non-pengion, debu, pelarut, gas, dan sebagainya. Setiap perangkat sering kali dirancang khusus untuk mengukur jenis kontaminan tertentu atau khusus.
Perangkat elektronik perlu dikalibrasi sebelum dan sesudah digunakan untuk memastikan keakuratan pengukuran yang dilakukan dan sering kali memerlukan sistem sertifikasi ketepatan instrumen.
Mengumpulkan data pajanan di tempat kerja membutuhkan sumber daya dan waktu yang banyak, dan dapat digunakan untuk berbagai tujuan, termasuk mengevaluasi kepatuhan terhadap peraturan pemerintah dan untuk merencanakan intervensi pencegahan. Kegunaan data pajanan di tempat kerja dipengaruhi oleh beberapa faktor berikut ini:
- Penyimpanan data (misalnya penggunaan basis data elektronik dan terpusat dengan penyimpanan semua catatan)
- Standarisasi pengumpulan data
- Kolaborasi antara peneliti, profesional keselamatan dan kesehatan, dan perusahaan asuransi
Pada tahun 2018, dalam upaya untuk menstandarkan pengumpulan data kebersihan industri di antara perusahaan asuransi kompensasi pekerja dan untuk menentukan kelayakan pengumpulan data IH yang dikumpulkan, formulir survei udara dan kebisingan IH dikumpulkan.
Bidang data dievaluasi berdasarkan tingkat kepentingannya dan daftar studi bidang inti dikembangkan, dan diserahkan kepada panel ahli untuk ditinjau sebelum finalisasi. Daftar studi inti akhir dibandingkan dengan rekomendasi yang diterbitkan oleh American Conference of Governmental Industrial Hygienists (ACGIH) dan American Industrial Hygiene Association (AIHA).12 Bidang data yang penting untuk menstandarkan pengumpulan data IH diidentifikasi dan diverifikasi. Bidang data “esensial” tersedia dan dapat berkontribusi pada peningkatan kualitas data dan pengelolaannya jika dimasukkan ke dalam sistem manajemen data IH.
Kanada dan beberapa negara Eropa telah bekerja untuk membangun basis data pajanan pekerjaan dengan elemen data standar dan kualitas data yang lebih baik. Basis data ini termasuk MEGA, COLCHIC, dan CWED.
Pengambilan sampel debu
Debu yang mengganggu dianggap sebagai total debu di udara termasuk fraksi yang dapat dihirup dan terhirup.
Terdapat berbagai metode pengambilan sampel debu yang diakui secara internasional. Debu yang dapat terhirup ditentukan dengan menggunakan alat ukur modern yang setara dengan monitor Institute of Occupational Medicine (IOM) MRE 113A (lihat bagian tentang pemaparan, pengukuran & pemodelan di tempat kerja).
Debu yang dapat terhirup dianggap sebagai debu berdiameter kurang dari 100 mikrometer setara diameter aerodinamis (AED) yang masuk melalui hidung dan atau mulut. Lihat Paru-Paru
Debu yang dapat terhirup diambil sampelnya dengan menggunakan desain pengambil sampel debu siklon untuk mengambil sampel fraksi debu AED tertentu pada laju aliran yang ditetapkan. Fraksi debu yang dapat terhirup adalah debu yang masuk ke dalam 'paru-paru dalam' dan dianggap kurang dari 10 mikrometer AED.
Fraksi debu yang mengganggu, yang dapat dihirup, dan yang dapat dihirup semuanya diambil sampelnya dengan menggunakan pompa volumetrik konstan untuk periode pengambilan sampel tertentu. Dengan mengetahui massa sampel yang dikumpulkan dan volume udara yang disampel, konsentrasi untuk fraksi yang disampel dapat diberikan dalam miligram (mg) per meter kubik (m3). Dari sampel tersebut, jumlah debu yang dapat terhirup atau terhirup dapat ditentukan dan dibandingkan dengan batas paparan kerja yang relevan.
Dengan menggunakan alat pengambil sampel yang dapat dihirup, terhirup, atau alat pengambil sampel lain yang sesuai (7 lubang, 5 lubang, dan sebagainya), metode pengambilan sampel debu ini juga dapat digunakan untuk menentukan paparan logam di udara. Hal ini memerlukan pengumpulan sampel pada filter metil-selulosa ester (MCE) dan pencernaan asam pada media pengumpul di laboratorium yang diikuti dengan pengukuran konsentrasi logam melalui spektrofotometri serapan atom (atau emisi). Laboratorium Kesehatan dan Keselamatan Kerja Inggris dan NIOSH Manual.
Metode Analitik memiliki metodologi khusus untuk berbagai macam logam di udara yang ditemukan dalam pemrosesan industri (peleburan, pengecoran, dan lain-lain).
Metode lebih lanjut tersedia untuk penentuan asbes, fiberglass, serat mineral sintetis, dan debu serat mineral keramik di udara. Metode ini adalah metode filter membran (MFM) dan memerlukan pengumpulan debu pada filter yang dilapisi untuk memperkirakan paparan dengan menghitung serat yang 'sesuai' dalam 100 bidang melalui mikroskop. Hasilnya dikuantifikasi berdasarkan jumlah serat per mililiter udara (f/ml). Banyak negara secara ketat mengatur metodologi yang diterapkan pada MFM.
Pengambilan sampel kimia
Dua jenis tabung penyerap kimia digunakan untuk mengambil sampel untuk berbagai macam zat kimia. Secara tradisional, 'tabung' penyerap bahan kimia (tabung kaca atau baja tahan karat berdiameter internal antara 2 hingga 10 mm) yang diisi dengan silika penyerap yang sangat halus (hidrofilik) atau karbon, seperti arang kelapa (lifosilik), digunakan dalam jalur pengambilan sampel di mana udara dialirkan melalui bahan penyerap antara empat jam (sampel tempat kerja minimum) hingga 24 jam (sampel lingkungan). Bahan hidrofilik mudah menyerap bahan kimia yang larut dalam air dan bahan lifofilik menyerap bahan yang tidak larut dalam air.
Bahan penyerap kemudian diekstraksi secara kimiawi atau fisika dan pengukuran dilakukan dengan menggunakan berbagai metode kromatografi gas atau spektrometri massa. Metode tabung penyerap ini memiliki keuntungan karena dapat digunakan untuk berbagai macam potensi kontaminasi. Namun, metode ini relatif mahal, memakan waktu dan membutuhkan keahlian yang signifikan dalam pengambilan sampel dan analisis kimia. Keluhan yang sering muncul dari para pekerja adalah keharusan untuk memakai pompa pengambilan sampel (hingga 1 kg) selama beberapa hari kerja untuk menyediakan data yang memadai untuk penentuan kepastian statistik yang diperlukan untuk menentukan paparan.
Dalam beberapa dekade terakhir, kemajuan telah dicapai dalam teknologi pengukur pajanan 'pasif'. Sampler ini sekarang dapat dibeli untuk mengukur satu bahan kimia (misalnya formaldehida) atau jenis bahan kimia (misalnya keton) atau spektrum bahan kimia yang luas (misalnya pelarut). Alat ini relatif mudah diatur dan digunakan. Namun, biaya yang cukup besar masih dapat dikeluarkan untuk analisis 'lencana'. Beratnya 20 hingga 30 gram dan para pekerja tidak mengeluhkan keberadaannya.
Sayangnya, 'lencana' mungkin tidak tersedia untuk semua jenis pengambilan sampel di tempat kerja yang mungkin diperlukan, dan metode arang atau silika terkadang harus diterapkan.
Dari metode pengambilan sampel, hasilnya dinyatakan dalam miligram per meter kubik (mg/m3) atau bagian per juta (PPM) dan dibandingkan dengan batas paparan kerja yang relevan.
Ini adalah bagian penting dari penentuan paparan bahwa metode pengambilan sampel untuk paparan kontaminan tertentu secara langsung terkait dengan standar paparan yang digunakan. Banyak negara mengatur standar pemaparan, metode yang digunakan untuk menentukan pemaparan, dan metode yang akan digunakan untuk analisis kimiawi atau analisis lain dari sampel yang dikumpulkan.
Pengambilan sampel kebisingan
Ada dua jenis kebisingan, yaitu Kebisingan Lingkungan, yang merupakan suara yang tidak diinginkan yang terjadi di luar ruangan, dan Kebisingan Kerja, yaitu suara yang diterima karyawan saat mereka berada di tempat kerja. Kebisingan lingkungan dapat berasal dari berbagai sumber tergantung pada aktivitas, lokasi, dan waktu. Kebisingan lingkungan dapat dihasilkan dari transportasi seperti lalu lintas jalan raya, kereta api, dan udara, atau layanan konstruksi dan bangunan, dan bahkan aktivitas rumah tangga dan rekreasi.
Terdapat batas legal untuk kebisingan yaitu Kebisingan Lingkungan adalah 70 dB(A) selama 24 jam paparan rata-rata.[21] Demikian pula, batas Kebisingan Kerja adalah 85 dB(A) menurut NIOSH, atau 90 dB(A) menurut OSHA untuk periode kerja 8 jam. [22] Untuk menegakkan batas-batas ini, berikut adalah metode untuk mengukur kebisingan, termasuk Sound Level Meter (SLM), Aplikasi Pengukur Tingkat Suara, Pengukur Tingkat Suara Terintegrasi (ISLM), Pengukur Tingkat Suara Impuls (SLM Impuls), Dosimeter Kebisingan, dan Pengukur Paparan Suara Pribadi (PSEM).
Sound Level Meter (SLM) mengukur tingkat suara pada satu titik waktu dan oleh karena itu memerlukan beberapa pengukuran yang harus dilakukan pada waktu yang berbeda dalam satu hari. SLM terutama digunakan untuk mengukur tingkat suara yang relatif stabil; ada peningkatan kesulitan dalam mengukur paparan suara rata-rata jika tingkat kebisingan sangat bervariasi.
Aplikasi Pengukur Tingkat Suara adalah program yang dapat diunduh ke perangkat seluler. Aplikasi ini menerima suara melalui mikrofon internal atau eksternal ponsel dan menampilkan pengukuran tingkat suara dari pengukur tingkat suara dan dosimeter kebisingan aplikasi.
Pengukur Tingkat Suara Terintegrasi (ISLM) mengukur tingkat suara yang setara dalam periode pengukuran. Karena ISLM mengukur kebisingan di area tertentu, maka sulit untuk mengukur paparan pribadi pekerja saat mereka bergerak di seluruh ruang kerja.
Pengukur Tingkat Suara Impuls (Impulse Sound Level Meter/ISLM) mengukur puncak dari setiap impuls suara. Kondisi yang paling optimal untuk mengukur puncak terjadi ketika hanya ada sedikit kebisingan latar belakang.
Dosimeter Kebisingan mengumpulkan tingkat suara untuk titik waktu tertentu, serta tingkat suara yang berbeda dari waktu ke waktu. Dosimeter kebisingan dapat mengukur tingkat paparan pribadi dan dapat digunakan di area dengan risiko kebakaran yang tinggi.
Personal Sound Exposure Meter (PSEM) dikenakan oleh karyawan saat mereka bekerja. Keuntungan dari PSEM adalah bahwa hal ini menghilangkan kebutuhan penilai kebisingan untuk menindaklanjuti dengan pekerja ketika penilai mengukur tingkat kebisingan di area kerja.
Kebisingan yang berlebihan dapat menyebabkan Gangguan Pendengaran Akibat Kerja. 12% pekerja melaporkan mengalami kesulitan pendengaran, menjadikannya penyakit kronis paling umum ketiga di A.S. Di antara para pekerja ini, 24% mengalami kesulitan pendengaran yang disebabkan oleh kebisingan di tempat kerja, dengan 8% dipengaruhi oleh tinitus, dan 4% mengalami kesulitan pendengaran dan tinitus.
Bahan kimia ototoksik termasuk pelarut, logam, senyawa, asfiksia, nitril, dan obat-obatan, dapat berkontribusi lebih jauh terhadap gangguan pendengaran.
Manajemen dan pengendalian pajanan
Hirarki pengendalian mendefinisikan pendekatan yang digunakan untuk mengurangi risiko paparan guna melindungi pekerja dan masyarakat. Metode-metode ini meliputi eliminasi, substitusi, kontrol teknik (isolasi atau ventilasi), kontrol administratif, dan alat pelindung diri. Ahli higiene kerja, insinyur, pemeliharaan, manajemen, dan karyawan harus diajak berkonsultasi untuk memilih dan merancang kontrol yang paling efektif dan efisien berdasarkan hierarki kontrol.
Masyarakat profesional
Perkembangan masyarakat higiene industri berasal dari Amerika Serikat, dimulai dengan pertemuan pertama para anggota untuk Konferensi Ahli Higiene Industri Pemerintah Amerika pada tahun 1938, dan pembentukan Asosiasi Higiene Industri Amerika pada tahun 1939. Di Inggris, British Occupational Hygiene Society dimulai pada tahun 1953. Selama bertahun-tahun, masyarakat pekerjaan profesional telah terbentuk di berbagai negara, yang mengarah pada pembentukan Asosiasi Higiene Perusahaan Internasional pada tahun 1987, untuk mempromosikan dan mengembangkan higiene perusahaan di seluruh dunia melalui organisasi-organisasi anggotanya.
IOHA telah berkembang menjadi 29 organisasi anggota, yang mewakili lebih dari 20.000 ahli higiene perusahaan di seluruh dunia, dengan representasi dari negara-negara yang ada di setiap benua.
Literatur yang ditinjau oleh rekan sejawat
Ada beberapa jurnal akademik yang secara khusus berfokus pada penerbitan studi dan penelitian di bidang kesehatan kerja. Journal of Occupational and Environmental Hygiene (JOEH) telah diterbitkan bersama sejak tahun 2004 oleh American Industrial Hygiene Association dan American Conference of Governmental Industrial Hygienists, menggantikan jurnal American Industrial Hygiene Association dan Applied Occupational & Environmental Hygiene sebelumnya.
Jurnal higiene kerja penting lainnya adalah The Annals of Occupational Hygiene, yang diterbitkan oleh British Occupational Hygiene Society sejak tahun 1958. Lebih lanjut, The National Institute for Occupational Safety and Health mengelola database bibliografi yang dapat dicari (NIOSHTIC-2) untuk publikasi, dokumen, laporan hibah, dan produk komunikasi lainnya tentang keselamatan dan kesehatan kerja.
Hirarki pengendalian adalah alat penting untuk menentukan cara mengendalikan bahaya yang paling efisien dan efektif di tempat kerja.
Higiene kerja sebagai karier

Sumber: en.wikipedia.org
Contoh karier higiene kerja meliputi:
- Petugas kepatuhan atas nama badan pengawas
- Profesional yang bekerja atas nama perusahaan untuk melindungi tenaga kerja
- Konsultan yang bekerja atas nama perusahaan
- Peneliti yang melakukan pekerjaan higiene kerja di laboratorium atau lapangan
Pendidikan
Dasar dari pengetahuan teknis higiene kerja berasal dari pelatihan yang kompeten di bidang ilmu pengetahuan dan manajemen berikut ini:
- Ilmu pengetahuan dasar (biologi, kimia, matematika (statistik), fisika);
- Penyakit akibat kerja (penyakit, cedera dan pengawasan kesehatan (biostatistik, epidemiologi, toksikologi));
- Bahaya kesehatan (bahaya biologi, kimia dan fisik, ergonomi dan faktor manusia);
- Lingkungan kerja (pertambangan, industri, manufaktur, transportasi dan penyimpanan, industri jasa dan perkantoran);
- Prinsip-prinsip manajemen program (etika profesional dan bisnis, metode investigasi di tempat kerja dan insiden, pedoman pemaparan, batas pemaparan di tempat kerja, peraturan berbasis yurisdiksi, identifikasi bahaya, penilaian risiko dan komunikasi risiko, manajemen data, evakuasi kebakaran, dan tanggap darurat lainnya);
- Praktik pengambilan sampel, pengukuran dan evaluasi (instrumentasi, protokol pengambilan sampel, metode atau teknik, kimia analitik);
- Pengendalian Bahaya (eliminasi, substitusi, rekayasa, administratif, APD dan Ventilasi Udara dan Ekstraksi);
- Lingkungan (polusi udara, limbah berbahaya).
Namun, bukan pengetahuan hafalan yang mengidentifikasi seorang ahli higiene kerja yang kompeten. Ada sebuah “seni” dalam menerapkan prinsip-prinsip teknis dengan cara yang memberikan solusi yang masuk akal untuk masalah-masalah di tempat kerja dan lingkungan. Pada dasarnya, seorang “mentor” yang berpengalaman, yang memiliki pengalaman dalam higiene kerja diharuskan untuk menunjukkan kepada ahli higiene kerja yang baru bagaimana menerapkan pengetahuan ilmiah dan manajemen yang telah dipelajari di tempat kerja dan masalah lingkungan untuk menyelesaikan masalah secara memuaskan.
Untuk menjadi ahli higiene kerja profesional, pengalaman dalam praktik seluas mungkin diperlukan untuk menunjukkan pengetahuan di bidang higiene kerja. Hal ini sulit dilakukan oleh “spesialis” atau mereka yang berpraktik di bidang yang sempit. Membatasi pengalaman pada mata pelajaran tertentu seperti remediasi asbes, ruang tertutup, kualitas udara dalam ruangan, atau pengurangan timbal, atau belajar hanya melalui buku teks atau “kursus tinjauan” dapat menjadi kerugian ketika diminta untuk menunjukkan kompetensi di bidang lain dalam higiene kerja.
Informasi yang disajikan di Wikipedia dapat dianggap hanya sebagai garis besar persyaratan untuk pelatihan higiene kerja profesional. Hal ini dikarenakan persyaratan aktual di negara, negara bagian atau wilayah mana pun dapat bervariasi karena sumber daya pendidikan yang tersedia, permintaan industri, atau persyaratan yang diamanatkan oleh peraturan.
Selama tahun 2010, Occupational Hygiene Training Association (OHTA) melalui sponsor yang disediakan oleh IOHA memprakarsai skema pelatihan bagi mereka yang berminat atau yang membutuhkan pelatihan higiene kerja. Modul-modul pelatihan ini dapat diunduh dan digunakan secara bebas. Modul-modul yang tersedia (Prinsip-prinsip Dasar dalam Higiene Perusahaan, Dampak Kesehatan dari Zat Berbahaya, Pengukuran Zat Berbahaya, Lingkungan Termal, Kebisingan, Asbes, Pengendalian, Ergonomi) ditujukan untuk tingkat 'dasar' dan 'menengah' dalam Higiene Perusahaan.
Meskipun modul-modul ini dapat digunakan secara bebas tanpa pengawasan, kehadiran di kursus pelatihan yang terakreditasi sangat dianjurkan. Modul-modul pelatihan ini tersedia di OH Learning.com
Program akademis yang menawarkan gelar sarjana atau magister higiene industri di Amerika Serikat dapat mengajukan permohonan kepada Dewan Akreditasi untuk Teknik dan Teknologi (ABET) agar program mereka diakreditasi. Pada 1 Oktober 2006, 27 institusi telah mengakreditasi program higiene industri mereka. Akreditasi tidak tersedia untuk program Doktoral.
Di Amerika Serikat, pelatihan para profesional IH didukung oleh Institut Nasional untuk Keselamatan dan Kesehatan Kerja melalui Pusat Pendidikan dan Penelitian NIOSH.
Disadur dari: en.wikipedia.org

Teknik Industri
Prosedur Pengendalian Persediaan Untuk Mengelola Persediaan Anda Secara Efisien
Dipublikasikan oleh Anjas Mifta Huda pada 10 Februari 2025
Kontrol inventaris selalu merupakan proses yang sulit tetapi merupakan aspek yang sangat penting dalam bisnis apa pun. Tidak ada yang bisa menjalankan bisnis dengan baik kecuali mereka tahu apa yang mereka miliki, apa yang telah terjual, dan berapa harga pokoknya. Pada artikel ini, kami akan memperkenalkan 11 prosedur pengendalian persediaan yang dapat Anda terapkan untuk mengelola persediaan Anda dengan lebih efisien.
Fitur-fitur pengendalian inventaris
Pengendalian inventaris, sering dikenal sebagai manajemen inventaris, adalah proses pemantauan stok gudang perusahaan untuk memastikan bahwa stok tersebut berada pada tingkat yang paling memadai. Ini mencakup proses pengelolaan barang dari saat dipesan, melalui penyimpanan, pemindahan di dalam gudang atau di gudang yang berbeda, serta ke tujuan akhir atau pembuangan. Manajemen inventaris adalah bagian penting dari setiap bisnis ritel. Ingin tahu seberapa penting laporan pergerakan inventaris?.
Sistem kontrol inventaris adalah pendekatan teknologi yang membantu bisnis untuk menjaga dan melacak komoditas melalui rantai pasokan. Teknologi ini akan mengintegrasikan dan mengelola pembelian, pengiriman, penerimaan, pergudangan, dan pengembalian barang ke dalam satu sistem. Mempraktikkan prosedur kontrol inventaris yang baik dapat membantu bisnis mengurangi banyak operasi manual yang mahal dan memakan waktu. Sistem ini akan menunjukkan kepada Anda berapa banyak persediaan yang Anda miliki, di mana lokasinya, dan kapan Anda perlu melakukan pemesanan ulang untuk mempertahankan tingkat stok yang ideal. Bagi UKM yang ingin mempelajari cara mengelola inventaris secara efisien, panduan infografis ini sangat direkomendasikan.
11 prosedur dan teknik kontrol inventaris

Sumber: magestore.com
Setiap bisnis akan menerapkan cara kontrol inventarisnya sendiri. Namun, pada akhirnya, mengelola stok secara efisien adalah target yang ingin dicapai semua orang. Ada beberapa prosedur umum dan praktik terbaik manajemen inventaris yang dapat menginstruksikan Anda tentang cara mengelola inventaris dengan lebih efisien.
Prioritaskan lokasi dan aksesibilitas
Pastikan gudang dan stok Anda terorganisir dengan baik dan mudah diakses karena akan mengurangi banyak waktu bagi staf untuk mencari lokasi dan menemukan produk. Dengan demikian, semua langkah selanjutnya dapat berjalan dengan lancar.
Tetapkan pengaturan lantai dan tata letak
Hal ini akan membantu pemilik dan staf untuk mengingat semua lokasi produk sehingga akan lebih mudah dan cepat untuk menemukan barang saat dibutuhkan. Selain itu, membuat denah lantai akan membantu Anda dalam menentukan lokasi terbaik untuk barang dagangan Anda.
Optimalkan dan perkirakan inventaris Anda
Cobalah untuk mengoptimalkan dan memperkirakan inventaris Anda dengan memastikan jumlah barang yang memadai, tidak terlalu sedikit atau terlalu banyak. Sebaiknya Anda juga membuat daftar barang yang laris yang lebih cepat terjual daripada yang lain. Terlepas dari musimnya, barang-barang ini harus selalu ada di gudang. Akan lebih mudah untuk mempersiapkan diri menghadapi masalah pasokan dan permintaan yang akan datang jika tingkat penjualan dipantau dan tren pasar diikuti.
Singkirkan stok yang tidak dibutuhkan
Cobalah untuk menyingkirkan barang-barang yang telah ada di gudang dalam jangka waktu yang lama dengan menjalankan promosi atau menawarkan diskon. Ini akan menciptakan lebih banyak ruang bagi Anda untuk menaruh barang lain yang dibutuhkan. Selain itu, penawaran semacam itu juga dapat meningkatkan kepuasan pelanggan, membuat pengisian ulang inventaris menjadi lebih mudah, dan membuat bisnis terus berjalan.
Tetapkan jadwal penghitungan siklus
Tetapkan jadwal penghitungan siklus untuk memantau aliran produk secara memadai daripada menunggu kesempatan untuk menghitung inventaris Anda.
Periksa stok dengan cepat setelah pengiriman
Setelah setiap pesanan inventaris tiba, luangkan waktu beberapa menit untuk memeriksa apakah barang dagangan yang Anda kirimkan sudah benar atau ada masalah dengan kualitas produk dan tolak barang yang tidak dipesan atau rusak. Langkah ini akan membantu Anda menghindari kasus stok yang sebenarnya tidak cukup atau melebihi data inventaris dari sistem.
Beri label pada semua produk
Label harus memiliki data yang cukup seperti nama produk, nomor, jumlah, dan deskripsi. Memberi label pada semua produk akan membuat Anda lebih mudah dan cepat mengenalinya.
Perhatikan tanggal kedaluwarsa
Ketika Anda memperhatikan tanggal kedaluwarsa produk, Anda dapat menyingkirkan barang dagangan yang tersisa sebelum kedaluwarsa dengan mengurangi harga atau menawarkan penawaran khusus.
Pastikan Anda melacak inventaris Anda
Anda perlu mengetahui berapa banyak stok yang Anda miliki, dari mana stok tersebut berasal, atau kapan barang meninggalkan gudang untuk menjalankan bisnis Anda. Jadi, sangat penting untuk melacak inventaris Anda sesering mungkin. Saat ini, hampir semua bisnis menggunakan perangkat lunak manajemen inventaris untuk membantu mereka melacak inventaris.
Menetapkan tanggung jawab manajemen inventaris
Ketika Anda menetapkan tanggung jawab manajemen inventaris terpisah untuk seseorang, mereka cenderung melakukan tugas dengan lebih baik. Ini karena mereka lebih fokus pada proses, menghabiskan lebih banyak waktu, dan lebih terbiasa.
Buat cadangan data inventaris Anda
Anda juga harus memastikan bahwa Anda memiliki cadangan data sehingga informasi penting selalu tersedia, dapat diakses, dan tidak pernah hilang. Dan, jika data hilang atau terhapus, Anda akan memiliki cadangan yang siap untuk dipulihkan, sehingga bisnis dan pelanggan Anda tidak dirugikan.
Bagaimana kontrol inventaris dapat memengaruhi bisnis Anda?

Sumber: magestore.com
Menggabungkan proses manajemen inventaris yang memadai dengan sistem Anda dapat membantu bisnis memastikan kesehatan keuangan dan tingkat stok yang memenuhi kebutuhan dan harapan pelanggan. Menurut netsuite.com, 62% pelanggan berhenti membeli dari sebuah perusahaan karena layanan pelanggan yang buruk. Frustrasi karena kehabisan stok atau barang yang dipesan lebih dulu berada di urutan teratas dalam daftar keluhan layanan pelanggan. Faktanya, menurut penelitian tentang toko serba ada, kehabisan stok dapat menyebabkan toko kehilangan satu dari setiap 100 konsumen. Selain itu, 55% pembeli di toko mana pun tidak akan membeli barang pengganti jika barang yang mereka inginkan tidak tersedia.
Selain itu, sistem kontrol stok yang baik juga dapat membantu bisnis mendapatkan informasi real-time tentang barang, mengurangi kerusakan, dan mengurangi biaya penyimpanan inventaris. Hasilnya, pemilik bisnis dapat menyimpan, melacak, mengirim, dan memesan inventaris atau stok dengan mempraktikkan prosedur kontrol inventaris standar untuk menghindari kerugian dan mengoptimalkan pendapatan.
Apa saja jenis-jenis sistem manajemen inventaris?

Sumber: magestore.com
Ada dua jenis utama sistem manajemen inventaris:
Sistem persediaan abadi
Sistem persediaan abadi mengharuskan bisnis untuk mengimplementasikan perangkat lunak dan peralatan pendukung sehingga lebih mahal daripada sistem persediaan periodik. Di sisi lain, sistem ini membantu memperbarui statistik inventaris secara teratur dan real-time. Metode kontrol inventaris ini menggunakan perangkat lunak point-of-sale dan manajemen aset untuk menentukan inventaris berdasarkan penjualan dan pembelian. Oleh karena itu, Anda akan selalu memiliki perhitungan stok yang tepat kapan pun Anda membutuhkannya dan pelacakan berkelanjutan juga membantu bisnis menghindari kehabisan stok.
Namun, masih ada beberapa kekurangan dengan sistem ini karena dijalankan oleh peralatan dan perangkat lunak. Peralatan yang mengalami kesalahan dan item yang dipindai dengan tidak benar dapat memengaruhi catatan inventaris. Selain itu, ada beberapa kasus yang tidak dapat dikenali oleh sistem seperti kerusakan, barang yang dicuri.
Sistem inventaris berkala
Sistem inventaris periodik cocok untuk bisnis kecil karena tidak memerlukan perangkat lunak yang rumit. Sistem ini mengandalkan penghitungan fisik persediaan secara berkala atau tidak berkala. Pemilik bisnis hanya melacak semua transaksi di akun pembelian. Setelah inventaris fisik selesai, saldo di akun pembelian ditransfer ke akun persediaan. Terakhir, Anda mencocokkan biaya stok akhir ke akun persediaan. Ada 2 metode untuk menghitung biaya persediaan: FIFO berarti stok pertama adalah yang dijual terlebih dahulu, dan LIFO berarti stok terakhir adalah yang dijual terlebih dahulu.
Kerugian dari sistem inventaris periodik berasal dari penghitungan fisik stok. Hal ini jelas akan meningkatkan biaya tenaga kerja karena bisnis harus mempekerjakan lebih banyak staf dan membayar lebih banyak waktu kerja. Selain itu, ada kemungkinan besar terjadi ketidaksesuaian inventaris dan kecurangan.
Kesimpulan
Secara umum, manajemen inventaris dapat memengaruhi keberhasilan atau kegagalan bisnis. Memiliki visibilitas yang tepat ke dalam stok Anda pada saat yang diperlukan sangat penting untuk kesuksesan. Untuk mendapatkan laporan inventaris yang real-time dan informatif untuk membuat rencana bisnis, penting untuk menerapkan prosedur kontrol inventaris yang tepat, bersama dengan alat dan perangkat lunak pendukung yang sesuai.
Disadur dari: magestore.com

Teknik Industri
Riset Operasi di Dunia Nyata
Dipublikasikan oleh Anjas Mifta Huda pada 10 Februari 2025
Pada bagian ini, beberapa contoh aplikasi riset operasi yang sukses di dunia nyata diberikan. Hal ini akan memberikan apresiasi kepada pembaca terhadap beragam jenis masalah yang dapat diatasi oleh O.R., dan juga besarnya penghematan yang dapat dilakukan. Tidak diragukan lagi, sumber terbaik untuk studi kasus dan rincian aplikasi yang berhasil adalah jurnal Interfaces, yang merupakan publikasi dari Institute for Operations Research and the Management Sciences (INFORMS). Jurnal ini berorientasi pada praktisi dan sebagian besar penjelasannya menggunakan istilah awam; pada titik tertentu, setiap insinyur industri yang berpraktik harus mengacu pada jurnal ini untuk menghargai kontribusi yang dapat diberikan oleh O.R.. Semua aplikasi yang ada di bawah ini diambil dari edisi terbaru Interfaces.
Sebelum menjelaskan aplikasi-aplikasi ini, beberapa kata akan menjelaskan posisi riset operasi di dunia nyata. Kenyataan yang tidak menguntungkan adalah bahwa O.R. telah menerima lebih dari sekadar publisitas negatif. Kadang-kadang dianggap sebagai ilmu esoterik yang tidak memiliki relevansi dengan dunia nyata, dan beberapa kritikus bahkan menyebutnya sebagai kumpulan teknik untuk mencari masalah yang harus dipecahkan! Jelas, kritik ini tidak benar dan ada banyak bukti yang terdokumentasi bahwa ketika diterapkan dengan benar dan dengan fokus pada masalah, O.R. dapat menghasilkan manfaat yang cukup spektakuler; contoh-contoh yang ada di bagian ini dengan jelas membuktikan fakta ini.
Di sisi lain, ada juga bukti yang menunjukkan bahwa (sayangnya) kritik yang dilontarkan terhadap O.R. tidak sepenuhnya tidak berdasar. Hal ini dikarenakan O.R. sering kali tidak diterapkan sebagaimana mestinya - orang sering kali berpandangan bahwa O.R. merupakan metode yang spesifik, bukan sebuah proses yang lengkap dan sistematis. Secara khusus, ada banyak sekali penekanan pada pemodelan dan langkah-langkah solusi, mungkin karena hal ini jelas menawarkan tantangan intelektual yang paling besar. Namun, sangat penting untuk mempertahankan fokus yang digerakkan oleh masalah - tujuan akhir dari studi O.R. adalah untuk mengimplementasikan solusi untuk masalah yang sedang dianalisis.
Membangun model kompleks yang pada akhirnya tidak dapat dipecahkan, atau mengembangkan prosedur solusi yang sangat efisien untuk model yang tidak memiliki relevansi dengan dunia nyata mungkin baik sebagai latihan intelektual, tetapi bertentangan dengan sifat praktis dari riset operasi! Sayangnya, fakta ini terkadang dilupakan. Kritik lain yang valid adalah kenyataan bahwa banyak analis yang terkenal buruk dalam mengkomunikasikan hasil proyek O.R. dalam hal yang dapat dipahami dan dihargai oleh praktisi yang mungkin tidak memiliki banyak kecanggihan matematika atau pelatihan formal dalam O.R. Intinya adalah bahwa proyek O.R. dapat berhasil hanya jika perhatian yang cukup diberikan pada masing-masing dari tujuh langkah proses dan hasilnya dikomunikasikan kepada pengguna akhir dalam bentuk yang dapat dimengerti.
Beberapa contoh proyek O.R. yang sukses sekarang disajikan.
Perencanaan Produksi di Harris Corporation - Bagian Semikonduktor: Untuk aplikasi pertama kami, kami melihat area yang mudah dihargai oleh setiap insinyur industri - perencanaan produksi dan kutipan tanggal jatuh tempo. Bagian semikonduktor Harris Corporation selama beberapa tahun merupakan bisnis yang cukup kecil yang melayani ceruk pasar di industri kedirgantaraan dan pertahanan di mana persaingannya sangat minim. Namun, pada tahun 1988, sebuah keputusan strategis dibuat untuk mengakuisisi lini produk semikonduktor dan fasilitas manufaktur General Electric.
Hal ini segera meningkatkan ukuran operasi dan lini produk Harris Semiconductor sekitar tiga kali lipat, dan yang lebih penting lagi, melambungkan Harris ke area pasar komersial seperti mobil dan telekomunikasi yang persaingannya sangat ketat. Dengan adanya keragaman lini produk yang baru dan peningkatan yang luar biasa dalam kompleksitas perencanaan produksi, Harris mengalami kesulitan untuk memenuhi jadwal pengiriman dan untuk tetap kompetitif dari segi finansial; jelas, diperlukan sistem yang lebih baik.
Pada fase orientasi, ditentukan bahwa sistem jenis MRP yang digunakan oleh sejumlah pesaingnya tidak akan menjadi jawaban yang memuaskan dan keputusan dibuat untuk mengembangkan sistem perencanaan yang akan memenuhi kebutuhan unik Harris - hasil akhirnya adalah IMPReSS, sebuah sistem perencanaan produksi dan penawaran pengiriman otomatis untuk seluruh jaringan produksi. Sistem ini merupakan kombinasi yang mengesankan dari heuristik serta teknik berbasis optimasi. Sistem ini bekerja dengan memecah masalah keseluruhan menjadi masalah yang lebih kecil dan lebih mudah dikelola dengan menggunakan pendekatan dekomposisi heuristik. Model matematika dalam masalah diselesaikan dengan menggunakan pemrograman linier bersama dengan konsep-konsep dari perencanaan kebutuhan material.
Seluruh sistem berinteraksi dengan basis data yang canggih yang memungkinkan untuk peramalan, penawaran dan entri pesanan, material dan informasi dinamis tentang kapasitas. Harris memperkirakan bahwa sistem ini telah meningkatkan pengiriman tepat waktu dari 75% menjadi 95% tanpa peningkatan persediaan, membantunya beralih dari kerugian sebesar $75 juta menjadi keuntungan sebesar $40 juta per tahun, dan memungkinkannya untuk merencanakan investasi modalnya dengan lebih efisien.
Pencampuran bensin di texaco: Untuk aplikasi lain dalam perencanaan produksi, tetapi kali ini dalam lingkungan produksi kontinu dan bukan produksi terpisah, kami melihat sistem yang digunakan di Texaco. Salah satu aplikasi utama O.R. adalah di bidang pencampuran bensin di kilang minyak bumi, dan hampir semua perusahaan minyak besar menggunakan model optimasi yang canggih di bidang ini. Di Texaco, sistem ini disebut StarBlend dan berjalan pada komputer mikro berjaringan. Sebagai latar belakang, penyulingan minyak mentah menghasilkan sejumlah produk yang berbeda pada suhu penyulingan yang berbeda. Masing-masing produk tersebut dapat dimurnikan lebih lanjut melalui perengkahan (di mana hidrokarbon yang kompleks dipecah menjadi hidrokarbon yang lebih sederhana) dan rekombinasi.
Berbagai aliran keluaran ini kemudian dicampur bersama untuk membentuk produk akhir seperti berbagai jenis bensin (bertimbal, tanpa timbal, super tanpa timbal, dll.), bahan bakar jet, diesel, dan minyak pemanas. Masalah perencanaannya sangat kompleks, karena kualitas minyak mentah yang berbeda menghasilkan konsentrasi aliran keluaran yang berbeda dan menimbulkan biaya yang berbeda, dan karena produk akhir yang berbeda menghasilkan pendapatan yang berbeda dan menggunakan sumber daya kilang yang berbeda pula. Mempertimbangkan hanya satu produk - bensin - ada berbagai properti yang membatasi campuran yang dihasilkan. Ini termasuk angka oktan, kandungan timbal dan sulfur, volatilitas, dan tekanan uap Reid, untuk menyebutkan beberapa di antaranya. Selain itu, kendala regulasi juga memberikan batasan tertentu.
Sebagai tanggapan awal terhadap masalah yang kompleks ini, pada awal hingga pertengahan tahun 1980-an, Texaco mengembangkan sebuah sistem yang disebut OMEGA. Inti dari sistem ini adalah model optimasi nonlinier yang mendukung sistem pendukung keputusan interaktif untuk pencampuran bensin secara optimal; sistem ini sendiri diperkirakan telah menghemat sekitar $30 juta per tahun bagi Texaco. StarBlend merupakan perluasan dari OMEGA ke lingkungan perencanaan multi periode di mana keputusan optimal dapat dibuat dalam jangka waktu perencanaan yang lebih panjang dibandingkan dengan satu periode.
Selain kendala kualitas campuran, model optimasi juga memasukkan kendala inventaris dan keseimbangan material untuk setiap periode dalam horison perencanaan. Pengoptimal menggunakan bahasa pemodelan aljabar yang disebut GAMS dan solver nonlinier yang disebut MINOS, bersama dengan sistem basis data relasional untuk mengelola data. Keseluruhan sistem berada dalam antarmuka yang mudah digunakan dan selain untuk perencanaan campuran langsung, sistem ini juga dapat digunakan untuk menganalisis berbagai skenario “bagaimana-jika” untuk masa depan dan untuk perencanaan jangka panjang.
Penjadwalan FMS di caterpillar: Untuk aplikasi ketiga, kami melihat penggunaan model simulasi. Model ini diterapkan untuk mendapatkan jadwal untuk Sistem Manufaktur Fleksibel (FMS) di Caterpillar, Inc. Pembaca yang tertarik dapat merujuk ke teks apa pun tentang manufaktur terintegrasi komputer untuk mengetahui detail tentang FMS; biasanya, FMS adalah sistem mesin CNC tujuan umum yang dihubungkan bersama oleh sistem penanganan material otomatis dan sepenuhnya dikontrol oleh komputer. FMS yang dimaksud di Caterpillar memiliki tujuh mesin milling CNC, stasiun fiksasi dan stasiun alat, dengan penanganan material dan alat dilakukan oleh empat kendaraan berpemandu otomatis (AGV) yang berjalan di sepanjang jalur kawat berpemandu satu arah. FMS dapat memberikan peningkatan kapasitas dan produktivitas yang luar biasa karena tingkat otomatisasi yang tinggi yang melekat di dalamnya dan potensinya untuk memproduksi berbagai macam komponen.
Di sisi lain, hal ini ada harganya; sistem ini juga sangat kompleks dan proses perencanaan dan penjadwalan produksi pada FMS dan kemudian mengendalikan operasinya bisa menjadi sangat sulit. Efisiensi prosedur penjadwalan yang digunakan dapat sangat berpengaruh pada besarnya manfaat yang diperoleh.
Di Caterpillar, analisis awal menunjukkan bahwa FMS kurang dimanfaatkan dan tujuan proyek ini adalah untuk menentukan jadwal produksi yang baik yang akan meningkatkan pemanfaatan dan meluangkan lebih banyak waktu untuk memproduksi suku cadang tambahan. Pada tahap orientasi, ditentukan bahwa lingkungan terlalu kompleks untuk direpresentasikan secara akurat melalui model matematika, dan oleh karena itu simulasi dipilih sebagai pendekatan pemodelan alternatif. Juga ditentukan bahwa meminimalkan makespan (yaitu waktu yang dibutuhkan untuk memproduksi semua kebutuhan harian) akan menjadi tujuan terbaik karena hal ini juga akan memaksimalkan dan menyeimbangkan pemanfaatan mesin.
Sebuah model simulasi yang terperinci kemudian dibangun dengan menggunakan bahasa khusus yang disebut SLAM. Selain rencana proses yang diperlukan untuk menentukan pemesinan aktual dari berbagai jenis suku cadang, model ini juga memperhitungkan sejumlah faktor seperti penanganan material, penanganan alat, dan fiksasi. Beberapa alternatif kemudian disimulasikan untuk mengamati bagaimana kinerja sistem dan ditentukan bahwa seperangkat aturan penjadwalan heuristik yang cukup sederhana dapat menghasilkan jadwal yang mendekati optimal dengan pemanfaatan mesin hampir 85%. Namun, yang lebih menarik adalah bahwa penelitian ini juga menunjukkan bahwa stabilitas jadwal sangat bergantung pada efisiensi alat potong yang digunakan oleh mesin.
Faktanya, ketika kualitas alat mulai menurun, sistem mulai menjadi semakin tidak stabil dan jadwal mulai tertinggal dari tanggal jatuh tempo. Untuk menghindari masalah ini, perusahaan harus menghentikan produksi selama akhir pekan dan mengganti alat yang sudah usang atau sesekali menggunakan waktu lembur untuk kembali ke jadwal. Poin utama yang perlu diperhatikan dari aplikasi ini adalah bahwa model simulasi dapat digunakan untuk menganalisis sistem yang sangat kompleks untuk sejumlah skenario bagaimana-jika dan untuk mendapatkan pemahaman yang lebih baik tentang dinamika sistem.
Penugasan armada di delta airlines: Salah satu area aplikasi O.R. yang paling menantang sekaligus bermanfaat adalah industri penerbangan. Kami menjelaskan secara singkat di sini salah satu aplikasi seperti itu di Delta Airlines. Masalah yang dipecahkan sering disebut sebagai masalah penugasan armada. Delta menerbangkan lebih dari 2500 penerbangan domestik setiap harinya dan menggunakan sekitar 450 pesawat dari 10 armada yang berbeda, dan tujuannya adalah untuk menugaskan pesawat ke dalam rute penerbangan sedemikian rupa sehingga pendapatan dari kursi dapat dimaksimalkan. Pengorbanannya cukup sederhana - jika sebuah pesawat terlalu kecil maka maskapai kehilangan potensi pendapatan dari penumpang yang tidak dapat ditampung di dalam pesawat, dan jika pesawat terlalu besar maka kursi yang tidak terisi merupakan pendapatan yang hilang (selain fakta bahwa pesawat yang lebih besar juga lebih mahal untuk dioperasikan).
Dengan demikian, tujuannya adalah untuk memastikan bahwa pesawat dengan ukuran yang “tepat” tersedia saat dibutuhkan dan di mana dibutuhkan. Sayangnya, memastikan bahwa hal ini dapat terjadi sangatlah rumit karena ada sejumlah masalah logistik yang membatasi ketersediaan pesawat pada waktu dan lokasi yang berbeda.
Masalah ini dimodelkan dengan program linear bilangan bulat campuran yang sangat besar - formulasi tipikal dapat menghasilkan sekitar 60.000 variabel dan 40.000 kendala. Horison perencanaan untuk setiap masalah adalah satu hari karena asumsinya adalah jadwal yang sama diulang setiap hari (pengecualian seperti jadwal akhir pekan ditangani secara terpisah). Tujuan utama dari masalah ini adalah untuk meminimalkan jumlah biaya operasional (termasuk biaya awak, biaya bahan bakar dan biaya pendaratan) dan biaya dari pendapatan penumpang yang hilang. Sebagian besar kendala bersifat struktural dan merupakan hasil dari pemodelan konservasi aliran pesawat dari armada yang berbeda ke lokasi yang berbeda di sekitar sistem pada waktu kedatangan dan keberangkatan yang berbeda.
Selain itu, terdapat kendala yang mengatur penugasan armada tertentu ke kaki tertentu dalam jadwal penerbangan. Ada juga kendala yang berkaitan dengan ketersediaan pesawat dalam armada yang berbeda, peraturan yang mengatur penugasan kru, persyaratan pemeliharaan terjadwal, dan pembatasan bandara. Seperti yang dapat dibayangkan oleh pembaca, tugas untuk mengumpulkan dan memelihara informasi yang diperlukan untuk menentukan secara matematis semua hal tersebut merupakan tugas yang luar biasa.
Meskipun membangun model seperti itu sulit tetapi bukan tidak mungkin, kemampuan untuk menyelesaikannya hingga optimal adalah hal yang mustahil hingga beberapa waktu yang lalu. Namun, O.R. komputasi telah berkembang hingga mencapai titik di mana sekarang memungkinkan untuk menyelesaikan model yang begitu rumit; sistem di Delta disebut Coldstart dan menggunakan implementasi yang sangat canggih untuk memecahkan masalah pemrograman linier dan integer. Manfaat finansial dari proyek ini sangat besar; sebagai contoh, menurut Delta, penghematan selama periode 1 Juni hingga 31 Agustus 1993 diperkirakan mencapai sekitar $220.000 per hari dibandingkan dengan jadwal yang lama.
Sistem manajemen keunggulan layanan keycorp: Untuk aplikasi terakhir kami, kami beralih ke sektor jasa dan industri yang mempekerjakan banyak insinyur industri - perbankan. Aplikasi ini menunjukkan bagaimana riset operasi digunakan untuk meningkatkan produktivitas dan kualitas layanan di KeyCorp, sebuah perusahaan induk bank yang berkantor pusat di Cleveland, Ohio. Dihadapkan pada persaingan yang semakin meningkat dari sumber-sumber nontradisional dan konsolidasi yang cepat di dalam industri perbankan, tujuan KeyCorp adalah untuk menyediakan serangkaian produk dan layanan keuangan kelas dunia dibandingkan dengan menjadi bank tradisional.
Elemen kunci untuk dapat melakukan hal ini secara efektif adalah layanan pelanggan berkualitas tinggi dan pertukaran alami yang dihadapi oleh manajer adalah dalam hal staf dan layanan - layanan yang lebih baik dalam bentuk waktu tunggu yang lebih singkat membutuhkan staf tambahan yang membutuhkan biaya lebih tinggi. Tujuan dari proyek ini adalah untuk menyediakan sistem pendukung keputusan yang lengkap bagi para manajer yang dijuluki SEMS (Sistem Manajemen Keunggulan Layanan).
Langkah pertama adalah pengembangan sistem terkomputerisasi untuk mengumpulkan data kinerja. Sistem ini merekam waktu awal dan akhir dari semua komponen transaksi teller, termasuk waktu respons host, waktu respons jaringan, waktu yang dikendalikan teller, waktu yang dikendalikan nasabah dan waktu perangkat keras cabang. Data yang dikumpulkan kemudian dapat dianalisis untuk mengidentifikasi area-area yang perlu ditingkatkan. Teori antrian digunakan untuk menentukan kebutuhan staf untuk tingkat layanan yang telah ditentukan.
Analisis ini menghasilkan peningkatan jumlah staf yang diperlukan yang tidak mungkin dilakukan dari sudut pandang biaya, dan oleh karena itu dibuat perkiraan pengurangan waktu pemrosesan yang diperlukan untuk memenuhi tujuan layanan dengan tingkat staf maksimum yang memungkinkan. Dengan menggunakan sistem pencatatan kinerja, KeyCorp kemudian dapat mengidentifikasi strategi untuk mengurangi berbagai komponen waktu layanan. Beberapa di antaranya melibatkan peningkatan teknologi, sementara yang lainnya berfokus pada peningkatan prosedural, dan hasilnya adalah pengurangan waktu pemrosesan transaksi sebesar 27%. Setelah lingkungan operasi stabil, KeyCorp memperkenalkan dua komponen utama SEMS untuk membantu para manajer cabang meningkatkan produktivitas.
Yang pertama, sistem Produktivitas Teller, memberikan ringkasan statistik dan laporan kepada manajer untuk membantu penempatan staf, penjadwalan, dan mengidentifikasi teller yang memerlukan pelatihan lebih lanjut. Yang kedua, sistem Waktu Tunggu Nasabah, memberikan informasi mengenai waktu tunggu nasabah per cabang, per hari dan per interval setengah jam di setiap cabang. Sistem ini menggunakan konsep-konsep dari statistik dan teori antrian untuk mengembangkan algoritma untuk menghasilkan informasi yang dibutuhkan.
Dengan menggunakan SEMS, manajer cabang dapat secara mandiri memutuskan strategi untuk meningkatkan layanan. Sistem ini secara bertahap diluncurkan ke semua cabang KeyCorp dan hasilnya sangat mengesankan. Sebagai contoh, secara rata-rata, waktu pemrosesan pelanggan berkurang hingga 53% dan waktu tunggu pelanggan menurun secara signifikan dengan hanya empat persen pelanggan yang menunggu lebih dari lima menit. Penghematan yang dihasilkan selama periode lima tahun diperkirakan mencapai $98 juta.
Ringkasan
Bab ini memberikan gambaran umum tentang riset operasi, asal-usulnya, pendekatannya dalam memecahkan masalah, dan beberapa contoh aplikasi yang berhasil. Dari sudut pandang seorang insinyur industri, O.R. adalah alat yang dapat melakukan banyak hal untuk meningkatkan produktivitas. Perlu ditekankan bahwa O.R. tidak bersifat esoterik atau tidak praktis, dan para insinyur yang tertarik untuk mempelajari topik ini lebih lanjut untuk teknik dan aplikasinya; potensi imbalannya bisa sangat besar.
Disadur dari: sites.pitt.edu

Teknik Industri
Pendekatan Riset Operasi
Dipublikasikan oleh Anjas Mifta Huda pada 10 Februari 2025
Mengingat bahwa O.R. merupakan sebuah kerangka kerja yang terintegrasi untuk membantu pengambilan keputusan, maka penting untuk memiliki pemahaman yang jelas mengenai kerangka kerja ini agar dapat diterapkan pada suatu masalah yang umum. Untuk mencapai hal ini, pendekatan yang disebut O.R. sekarang dirinci. Pendekatan ini terdiri dari tujuh langkah berurutan berikut ini:
- Orientasi.
- Definisi masalah.
- Pengumpulan data.
- Perumusan model.
- Solusi.
- Validasi model dan analisis keluaran.
- Implementasi dan pemantauan.
Menghubungkan setiap langkah ini menjadi sebuah mekanisme untuk umpan balik yang berkesinambungan; Gambar 1 menunjukkan hal ini secara skematis.
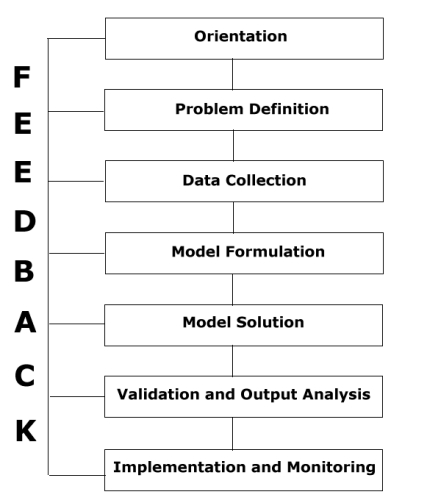
Sumber: sites.pitt.edu Gambar 1: Pendekatan Riset Operasi
Meskipun sebagian besar penekanan akademis adalah pada Langkah 4, 5 dan 6, pembaca harus mengingat fakta bahwa langkah-langkah lainnya juga sama pentingnya dari sudut pandang praktis. Memang, kurangnya perhatian pada langkah-langkah ini telah menjadi alasan mengapa O.R. terkadang secara keliru dianggap tidak praktis atau tidak efektif di dunia nyata.
Masing-masing langkah ini sekarang dibahas secara lebih rinci. Untuk mengilustrasikan bagaimana langkah-langkah tersebut dapat diterapkan, pertimbangkan skenario tipikal di mana sebuah perusahaan manufaktur merencanakan produksi untuk bulan yang akan datang. Perusahaan menggunakan berbagai sumber daya (seperti tenaga kerja, mesin produksi, bahan baku, modal, pemrosesan data, ruang penyimpanan, dan peralatan penanganan material) untuk membuat sejumlah produk berbeda yang bersaing untuk mendapatkan sumber daya ini. Produk-produk tersebut memiliki margin keuntungan yang berbeda dan membutuhkan jumlah yang berbeda dari setiap sumber daya. Banyak sumber daya yang ketersediaannya terbatas. Selain itu, terdapat faktor-faktor lain yang menyulitkan seperti ketidakpastian dalam permintaan produk, kerusakan mesin secara acak, dan perjanjian dengan serikat pekerja yang membatasi penggunaan tenaga kerja. Mengingat lingkungan operasi yang kompleks ini, tujuan keseluruhannya adalah merencanakan produksi bulan depan sehingga perusahaan dapat merealisasikan keuntungan semaksimal mungkin sekaligus berakhir di posisi yang baik untuk bulan berikutnya.
Sebagai ilustrasi tentang bagaimana seseorang dapat melakukan studi riset operasi untuk mengatasi situasi ini, pertimbangkan contoh yang sangat disederhanakan dari masalah perencanaan produksi di mana ada dua lini produk utama (widget dan gizmos, misalnya) dan tiga sumber daya pembatas utama (A, B dan C, misalnya) di mana masing-masing produk bersaing. Setiap produk membutuhkan jumlah yang berbeda-beda dari setiap sumber daya dan perusahaan mengeluarkan biaya yang berbeda (tenaga kerja, bahan baku, dll.) dalam membuat produk dan merealisasikan pendapatan yang berbeda saat produk tersebut dijual. Tujuan dari proyek O.R. adalah untuk mengalokasikan sumber daya ke dua produk secara optimal.
Orientasi: Langkah pertama dalam pendekatan O.R. disebut sebagai orientasi masalah. Tujuan utama dari langkah ini adalah untuk membentuk tim yang akan menangani masalah yang dihadapi dan memastikan bahwa semua anggotanya memiliki gambaran yang jelas tentang isu-isu yang relevan. Perlu dicatat bahwa karakteristik yang membedakan dari setiap studi O.R. adalah bahwa studi ini dilakukan oleh tim multifungsi. Sedikit menyimpang, menarik juga bahwa dalam beberapa tahun terakhir banyak hal yang telah ditulis dan dikatakan tentang manfaat tim proyek dan bahwa hampir semua proyek industri saat ini dilakukan oleh tim multifungsi. Bahkan dalam pendidikan teknik, kerja tim telah menjadi unsur penting dari materi yang diajarkan kepada siswa dan hampir semua program teknik akademis mengharuskan proyek tim siswa mereka. Pendekatan tim dari O.R. dengan demikian merupakan fenomena yang sangat alami dan diinginkan.
Biasanya, tim akan memiliki seorang pemimpin dan terdiri dari anggota dari berbagai bidang fungsional atau departemen yang akan terpengaruh oleh atau memiliki efek pada masalah yang dihadapi. Pada fase orientasi, tim biasanya bertemu beberapa kali untuk mendiskusikan semua masalah yang ada dan untuk mendapatkan fokus pada masalah-masalah yang kritis. Fase ini juga melibatkan studi dokumen dan literatur yang relevan dengan masalah untuk menentukan apakah ada orang lain yang mengalami masalah yang sama (atau serupa) di masa lalu, dan jika ada, untuk menentukan dan mengevaluasi apa yang telah dilakukan untuk mengatasi masalah tersebut.
Hal ini merupakan poin yang sering kali cenderung diabaikan, namun untuk mendapatkan solusi yang tepat waktu, sangat penting untuk tidak mengulang dari awal. Dalam banyak penelitian O.R., seseorang sebenarnya mengadaptasi prosedur solusi yang telah dicoba dan diuji, dibandingkan dengan mengembangkan prosedur yang sama sekali baru. Tujuan dari fase orientasi adalah untuk mendapatkan pemahaman yang jelas tentang masalah dan hubungannya dengan berbagai aspek operasional sistem, dan untuk mencapai konsensus tentang apa yang harus menjadi fokus utama proyek. Selain itu, tim juga harus memiliki apresiasi terhadap apa (jika ada) yang telah dilakukan di tempat lain untuk memecahkan masalah yang sama (atau serupa).
Dalam contoh perencanaan produksi hipotetis kami, tim proyek dapat terdiri dari anggota dari bidang teknik (untuk memberikan informasi tentang proses dan teknologi yang digunakan untuk produksi), perencanaan produksi (untuk memberikan informasi tentang waktu pemesinan, tenaga kerja, inventaris, dan sumber daya lainnya), penjualan dan pemasaran (untuk memberikan masukan tentang permintaan produk), akuntansi (untuk memberikan informasi tentang biaya dan pendapatan), dan sistem informasi (untuk menyediakan data terkomputerisasi). Tentu saja, insinyur industri bekerja di semua bidang ini.
Selain itu, tim mungkin juga memiliki personel di lantai pabrik seperti mandor atau pengawas shift dan mungkin akan dipimpin oleh manajer tingkat menengah yang memiliki hubungan dengan beberapa area fungsional yang tercantum di atas. Pada akhir fase orientasi, tim mungkin memutuskan bahwa tujuan spesifiknya adalah untuk memaksimalkan keuntungan dari dua produknya selama satu bulan ke depan. Tim ini juga dapat menentukan hal-hal tambahan yang diinginkan, seperti tingkat persediaan minimum untuk kedua produk pada awal bulan berikutnya, tingkat tenaga kerja yang stabil, atau tingkat pemanfaatan mesin yang diinginkan.
Definisi masalah: Ini adalah langkah kedua, dan dalam banyak kasus, langkah tersulit dalam proses O.R.. Tujuannya di sini adalah untuk menyempurnakan pertimbangan lebih lanjut dari fase orientasi ke titik di mana ada definisi yang jelas tentang masalah dalam hal cakupannya dan hasil yang diinginkan. Fase ini tidak boleh disamakan dengan fase sebelumnya karena fase ini jauh lebih terfokus dan berorientasi pada tujuan; namun, orientasi yang jelas sangat membantu dalam memperoleh fokus ini. Sebagian besar insinyur industri yang berpraktik dapat memahami perbedaan ini dan kesulitan dalam beralih dari tujuan umum seperti “meningkatkan produktivitas” atau “mengurangi masalah kualitas” ke tujuan yang lebih spesifik dan terdefinisi dengan baik yang akan membantu dalam memenuhi tujuan ini.
Definisi yang jelas tentang masalah memiliki tiga komponen yang luas. Yang pertama adalah pernyataan tujuan yang jelas. Bersamaan dengan spesifikasi tujuan, penting juga untuk mendefinisikan cakupannya, yaitu menetapkan batasan untuk analisis yang akan dilakukan. Meskipun solusi tingkat sistem yang lengkap selalu diinginkan, hal ini sering kali tidak realistis ketika sistemnya sangat besar atau kompleks dan dalam banyak kasus, kita harus fokus pada bagian sistem yang dapat diisolasi dan dianalisis secara efektif. Dalam kasus seperti itu, penting untuk diingat bahwa ruang lingkup solusi yang diperoleh juga akan dibatasi. Beberapa contoh tujuan yang tepat adalah
- Memaksimalkan keuntungan selama kuartal berikutnya dari penjualan produk kami.
- Meminimalkan rata-rata waktu henti di pusat kerja X.
- Meminimalkan total biaya produksi di Pabrik Y.
- Meminimalkan jumlah rata-rata pengiriman terlambat per bulan ke pelanggan.
Komponen kedua dari definisi masalah adalah spesifikasi faktor-faktor yang akan mempengaruhi tujuan. Faktor-faktor tersebut harus diklasifikasikan lebih lanjut ke dalam alternatif tindakan yang berada di bawah kendali pengambil keputusan dan faktor-faktor yang tidak dapat dikendalikan yang tidak dapat dikontrol. Sebagai contoh, dalam lingkungan produksi, tingkat produksi yang direncanakan dapat dikontrol, tetapi permintaan pasar yang sebenarnya mungkin tidak dapat diprediksi (meskipun mungkin dapat diperkirakan secara ilmiah dengan akurasi yang wajar). Idenya di sini adalah untuk membentuk daftar komprehensif dari semua tindakan alternatif yang dapat diambil oleh pengambil keputusan dan yang kemudian akan berdampak pada tujuan yang telah ditetapkan. Pada akhirnya, pendekatan O.R. akan mencari tindakan tertentu yang dapat mengoptimalkan tujuan.
Komponen ketiga dan terakhir dari definisi masalah adalah spesifikasi batasan-batasan tindakan, yaitu menetapkan batasan-batasan untuk tindakan spesifik yang dapat diambil oleh pengambil keputusan. Sebagai contoh, dalam lingkungan produksi, ketersediaan sumber daya dapat menentukan batasan tingkat produksi yang dapat dicapai. Ini adalah salah satu aktivitas di mana fokus tim multifungsi dari O.R. sangat berguna karena batasan yang dihasilkan oleh satu area fungsional sering kali tidak terlihat oleh orang-orang di area fungsional lainnya. Secara umum, merupakan ide yang baik untuk memulai dengan daftar panjang dari semua kendala yang mungkin terjadi dan kemudian mempersempitnya menjadi kendala yang jelas berpengaruh pada tindakan yang dapat dipilih. Tujuannya adalah untuk menjadi komprehensif namun tetap sederhana ketika menentukan batasan.
Melanjutkan ilustrasi hipotetis kita, tujuannya mungkin untuk memaksimalkan keuntungan dari penjualan kedua produk. Alternatif tindakannya adalah jumlah masing-masing produk yang akan diproduksi bulan depan, dan alternatif tersebut mungkin dibatasi oleh fakta bahwa jumlah masing-masing dari ketiga sumber daya yang diperlukan untuk memenuhi produksi yang direncanakan tidak boleh melebihi ketersediaan sumber daya yang diharapkan. Asumsi yang dapat dibuat di sini adalah bahwa semua unit yang diproduksi dapat dijual. Perhatikan bahwa pada titik ini seluruh masalah dinyatakan dalam kata-kata; nantinya pendekatan O.R. akan menerjemahkannya ke dalam model analitis.
Pengumpulan data: Pada tahap ketiga dari proses O.R., data dikumpulkan dengan tujuan untuk menerjemahkan masalah yang telah didefinisikan pada tahap kedua ke dalam sebuah model yang kemudian dapat dianalisis secara obyektif. Data biasanya berasal dari dua sumber - observasi dan standar. Yang pertama berhubungan dengan kasus di mana data benar-benar dikumpulkan dengan mengamati sistem yang sedang beroperasi dan biasanya, data ini cenderung berasal dari teknologi sistem. Misalnya, waktu operasi dapat diperoleh melalui studi waktu atau analisis metode kerja, penggunaan sumber daya atau tingkat sisa dapat diperoleh dengan melakukan pengukuran sampel selama beberapa interval waktu yang sesuai, dan data tentang permintaan dan ketersediaan dapat diperoleh dari catatan penjualan, pesanan pembelian, dan basis data inventaris.
Data lainnya diperoleh dengan menggunakan standar; banyak informasi terkait biaya yang cenderung termasuk dalam kategori ini. Sebagai contoh, sebagian besar perusahaan memiliki nilai standar untuk item biaya seperti tingkat upah per jam, biaya penyimpanan inventaris, harga jual, dan lain-lain; standar ini kemudian harus dikonsolidasikan dengan tepat untuk menghitung biaya berbagai aktivitas. Kadang-kadang, data juga dapat diminta secara tegas untuk masalah yang sedang dihadapi melalui penggunaan survei, kuesioner atau instrumen psikometrik lainnya.
Salah satu kekuatan pendorong utama di balik pertumbuhan O.R. adalah pertumbuhan yang cepat dalam teknologi komputer dan pertumbuhan yang bersamaan dalam sistem informasi serta penyimpanan dan pengambilan data secara otomatis. Hal ini merupakan keuntungan besar, karena analis O.R. sekarang memiliki akses siap pakai ke data yang sebelumnya sangat sulit diperoleh. Pada saat yang sama, hal ini juga menyulitkan karena banyak perusahaan yang berada dalam situasi kaya data namun miskin informasi. Dengan kata lain, meskipun semua data ada di “suatu tempat” dan dalam “beberapa bentuk”, mengekstrak informasi yang berguna dari sumber-sumber ini seringkali sangat sulit. Inilah salah satu alasan mengapa spesialis sistem informasi sangat berharga bagi tim yang terlibat dalam proyek O.R. yang tidak sepele. Pengumpulan data dapat memiliki efek penting pada langkah sebelumnya yaitu definisi masalah dan juga pada langkah selanjutnya yaitu perumusan model.
Untuk menghubungkan pengumpulan data dengan contoh produksi hipotetis kami, berdasarkan biaya variabel produksi dan harga jual masing-masing produk, dapat ditentukan bahwa keuntungan dari penjualan satu alat adalah $ 10 dan satu widget adalah $ 9. Dapat ditentukan berdasarkan pengukuran waktu dan pekerjaan bahwa setiap alat dan setiap widget masing-masing membutuhkan 7/10 unit dan 1 unit sumber daya 1, 1 unit dan 2/3 unit sumber daya 2, serta 1/10 unit dan 1/4 unit sumber daya 3. Akhirnya, berdasarkan komitmen sebelumnya dan data historis tentang ketersediaan sumber daya, dapat ditentukan bahwa pada bulan berikutnya akan ada 630 unit sumber daya 1, 708 unit sumber daya 2, dan 135 unit sumber daya 3 yang tersedia untuk digunakan dalam memproduksi kedua produk tersebut.
Perlu ditekankan bahwa ini hanyalah contoh ilustrasi yang sangat disederhanakan dan angka-angka di sini serta metode pengumpulan data yang disarankan juga sangat disederhanakan. Dalam praktiknya, angka-angka seperti ini sering kali sangat sulit untuk diperoleh secara tepat, dan nilai akhir biasanya didasarkan pada analisis sistem yang ekstensif dan mewakili kompromi yang disetujui oleh semua orang dalam tim proyek. Sebagai contoh, seorang manajer pemasaran mungkin mengutip data produksi historis atau data dari lingkungan yang serupa dan cenderung memperkirakan ketersediaan sumber daya dalam istilah yang sangat optimis. Di sisi lain, seorang perencana produksi mungkin mengutip tingkat skrap atau waktu henti mesin dan menghasilkan estimasi yang jauh lebih konservatif untuk hal yang sama. Perkiraan akhir mungkin akan mewakili kompromi di antara keduanya yang dapat diterima oleh sebagian besar anggota tim.
Formulasi model: Ini adalah fase keempat dari proses O.R.. Fase ini juga merupakan fase yang perlu mendapat banyak perhatian karena pemodelan adalah karakteristik yang menentukan dari semua proyek riset operasi. Istilah “model” disalahpahami oleh banyak orang, dan oleh karena itu dijelaskan secara rinci di sini. Sebuah model dapat didefinisikan secara formal sebagai abstraksi selektif dari realitas. Definisi ini menyiratkan bahwa pemodelan adalah proses menangkap karakteristik yang dipilih dari suatu sistem atau proses dan kemudian menggabungkannya ke dalam representasi abstrak dari aslinya. Gagasan utama di sini adalah bahwa biasanya jauh lebih mudah untuk menganalisis model yang disederhanakan daripada menganalisis sistem aslinya, dan selama model tersebut merupakan representasi yang cukup akurat, kesimpulan yang diambil dari analisis semacam itu dapat diekstrapolasi secara valid kembali ke sistem aslinya.
Tidak ada satu cara yang “benar” untuk membangun sebuah model dan seperti yang sering dicatat, pembangunan model lebih merupakan seni daripada ilmu pengetahuan. Poin penting yang perlu diingat adalah bahwa sering kali terdapat trade-off alami antara keakuratan model dan traktabilitasnya. Di satu sisi, dimungkinkan untuk membangun model yang sangat komprehensif, terperinci dan tepat dari sistem yang sedang dihadapi; ini memiliki fitur yang jelas diinginkan sebagai representasi yang sangat realistis dari sistem asli. Meskipun proses pembuatan model yang begitu rinci sering kali dapat membantu dalam memahami sistem dengan lebih baik, model ini mungkin tidak berguna dari perspektif analitis karena konstruksinya mungkin sangat memakan waktu dan kerumitannya menghalangi analisis yang berarti.
Di sisi lain, seseorang dapat membangun model yang kurang komprehensif dengan banyak asumsi penyederhanaan sehingga dapat dianalisis dengan mudah. Namun, bahayanya di sini adalah bahwa model tersebut mungkin kurang akurat sehingga ekstrapolasi hasil dari analisis kembali ke sistem asli dapat menyebabkan kesalahan yang serius. Jelasnya, kita harus menarik garis di suatu tempat di tengah-tengah di mana model merupakan representasi yang cukup akurat dari sistem asli, namun tetap dapat digunakan. Mengetahui di mana harus menarik garis tersebut adalah hal yang menentukan pemodel yang baik, dan ini adalah sesuatu yang hanya dapat diperoleh dengan pengalaman. Dalam definisi formal model yang diberikan di atas, kata kuncinya adalah “selektif”. Memiliki definisi masalah yang jelas memungkinkan seseorang untuk lebih menentukan aspek-aspek penting dari suatu sistem yang harus dipilih untuk direpresentasikan oleh model, dan tujuan utamanya adalah untuk sampai pada model yang menangkap semua elemen kunci dari sistem sambil tetap cukup sederhana untuk dianalisis.
Disadur dari: sites.pitt.edu

Teknik Industri
Apa itu Chemical Engineering (diklatkerja)
Dipublikasikan oleh Muhammad Reynaldo Saputra pada 10 Februari 2025
Chemical Engineering atau Teknik Kimia
Teknik kimia adalah bidang teknik yang berhubungan dengan studi operasi dan desain pabrik kimia serta metode peningkatan produksi. Insinyur kimia mengembangkan proses komersial yang ekonomis untuk mengubah bahan mentah menjadi produk yang bermanfaat. Teknik kimia menggunakan prinsip kimia, fisika, matematika, biologi, dan ekonomi untuk menggunakan, memproduksi, merancang, mengangkut, dan mengubah energi dan material secara efisien. Pekerjaan insinyur kimia dapat berkisar dari pemanfaatan nanoteknologi dan bahan nano di laboratorium hingga proses industri skala besar yang mengubah bahan kimia, bahan baku, sel hidup, mikroorganisme, dan energi menjadi bentuk dan produk yang berguna. Insinyur kimia terlibat dalam banyak aspek desain dan operasi pabrik, termasuk penilaian keselamatan dan bahaya, desain dan analisis proses, pemodelan, teknik kontrol, teknik reaksi kimia, teknik nuklir, teknik biologi, spesifikasi konstruksi, dan instruksi pengoperasian.
Desain Teknik Kimia
Desain teknik kimia menyangkut pembuatan rencana, spesifikasi, dan analisis ekonomi untuk pabrik percontohan, pabrik baru, atau modifikasi pabrik. Insinyur desain sering bekerja sebagai konsultan, merancang pabrik untuk memenuhi kebutuhan klien. Desain dibatasi oleh beberapa faktor, termasuk pendanaan, peraturan pemerintah, dan standar keselamatan. Kendala-kendala ini menentukan pilihan proses, bahan,
Sumber : Wikipedia

Teknik Industri
Sering Mendengar Istilah Ergonomis, Tapi Sudahkah Anda Memahami Maknanya?
Dipublikasikan oleh Muhammad Reynaldo Saputra pada 10 Februari 2025
Dalam dunia otomotif, pasti sering mendengar istilah ergonomis. Terutama ketika mendeskripsikan sebuah kenyamanan duduk di kabin mobil. Semakin nyaman mobil itu, berarti perancang mobil menerapkan konsep ergonomis dengan baik, tentu sesuai dengan pasar di mana kendaraan itu dijual. Dealer Technical Support Dept. Head PT TAM, Didi Ahadi, coba menjelaskan makna ergonomis dalam kebutuhan berkendara.
Desain yang disebut ergonomis, mampu menjamin pengemudi dan penumpang untuk merasa nyaman dan aman selama perjalanan. “Ergonomis terkait dengan tubuh manusia saat berinteraksi di dalam kendaraan. Kalau tidak ergonomis, bisa menyebabkan beberapa bagian tubuh merasa sakit atau bisa dikatakan pegal-pegal, di leher maupun di pundak. Jadi kita perlu memeriksa segala aspek dari aktivitas manusia di dalam mobil,” ujar Didi kepada Kompas.com, Senin (7/9/2020). Selain itu, kata Didi, yang tergolong dalam katagori ekonomis, yaitu bagaimana memposisikan instrumen di dalam kendaraan, tombol pengaturan, panel indikator atau fitur-fitur yang ada di dalam mobil di posisi yang tepat.
Apakah semua itu bisa dioperasikan dengan mudah dari bangku pengemudi atau penumpang sehingga memberikan kenyamanan dan keamanan? Oleh sebab itu, ketika akan membeli mobil, jangan pernah abaikan pertimbangan sisi “ergonomis”. Seperti salah satunya, apakah bangku mobil bisa disesuaikan dengan posisi berkendara yang nyaman sesuai dengan postur tubuh. “Serta tidak kerepotan dan kesulitan saat menginjak pedal (gas, rem, kopling), melihat ke depan dan ke kaca spion kanan, kiri serta belakang, atau menjangkau instrumen di dalam mobil.
Sumber: kompas.com
