Information Engineering
Teknik Informasi (bidang)
Dipublikasikan oleh Viskha Dwi Marcella Nanda pada 17 Februari 2025
Teknik informasi adalah disiplin teknik yang berhubungan dengan pembangkitan, distribusi, analisis, dan penggunaan informasi, data, dan pengetahuan dalam sistem. Bidang pertama kali dapat diidentifikasi pada awal abad ke-21.
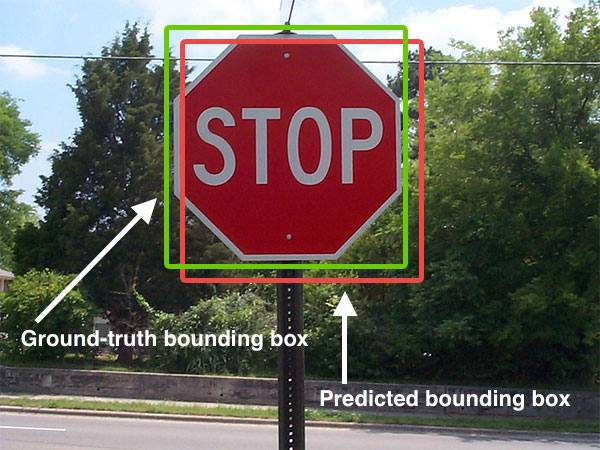
Deteksi objek untuk tanda berhenti.
Komponen rekayasa informasi mencakup bidang yang lebih teoretis seperti pembelajaran mesin, kecerdasan buatan, teori kontrol, pemrosesan sinyal, dan teori informasi, dan bidang yang lebih terapan seperti visi komputer, pemrosesan bahasa alami, bioinformatika, komputasi citra medis, cheminformatics, robotika otonom , robotika seluler, dan telekomunikasi. Banyak di antaranya berasal dari ilmu komputer, serta cabang teknik lainnya seperti teknik komputer, teknik elektro, dan bioteknologi.

Contoh pengelompokan dalam pembelajaran mesin.
Bidang teknik informasi sangat didasarkan pada matematika, khususnya probabilitas, statistik, kalkulus, aljabar linier, optimasi, persamaan diferensial, kalkulus variasi, dan analisis kompleks.
Insinyur informasi sering memegang gelar di bidang teknik informasi atau bidang terkait, dan sering menjadi bagian dari badan profesional seperti Institusi Teknik dan Teknologi atau Institut Pengukuran dan Kontrol. Mereka dipekerjakan di hampir semua industri karena meluasnya penggunaan rekayasa informasi.
Sejarah
Pada 1980-an/1990-an istilah rekayasa informasi mengacu pada bidang rekayasa perangkat lunak yang kemudian dikenal sebagai rekayasa data pada 2010-an/2020-an.
Elemen
Pembelajaran mesin dan statistik
Pembelajaran mesin adalah bidang yang melibatkan penggunaan metode statistik dan probabilistik untuk membiarkan komputer "belajar" dari data tanpa diprogram secara eksplisit. Ilmu data melibatkan penerapan pembelajaran mesin untuk mengekstrak pengetahuan dari data.
Subbidang pembelajaran mesin meliputi pembelajaran mendalam, pembelajaran terawasi, pembelajaran tanpa pengawasan, pembelajaran penguatan, pembelajaran semi-terawasi, dan pembelajaran aktif.
Inferensi kausal adalah komponen terkait lainnya dari rekayasa informasi.
Teori kontrol
Teori kontrol mengacu pada kontrol (kontinu) sistem dinamis, dengan tujuan untuk menghindari penundaan, overshoot, atau ketidakstabilan. Insinyur informasi cenderung lebih fokus pada teori kontrol daripada desain fisik sistem kontrol dan sirkuit (yang cenderung jatuh di bawah teknik listrik).
Subbidang teori kontrol meliputi kontrol klasik, kontrol optimal, dan kontrol nonlinier.
Pemrosesan sinyal
Pemrosesan sinyal mengacu pada pembangkitan, analisis, dan penggunaan sinyal, yang dapat mengambil banyak bentuk seperti gambar, suara, listrik, atau biologis.

Contoh bagaimana transformasi Fourier 2D dapat digunakan untuk menghapus informasi yang tidak diinginkan dari pemindaian sinar-X.
Teori informasi
Teori informasi mempelajari analisis, transmisi, dan penyimpanan informasi. Subbidang utama teori informasi termasuk pengkodean dan kompresi data.
Visi komputer
Visi komputer adalah bidang yang berhubungan dengan membuat komputer memahami data gambar dan video pada tingkat tinggi.
Pemrosesan bahasa alami
Pemrosesan bahasa alami berkaitan dengan membuat komputer memahami bahasa manusia (alami) pada tingkat tinggi. Ini biasanya berarti teks, tetapi juga sering mencakup pemrosesan ucapan dan pengenalan.
Bioinformatika
Bioinformatika adalah bidang yang berhubungan dengan analisis, pengolahan, dan penggunaan data biologis. Ini biasanya berarti topik seperti genomik dan proteomik, dan terkadang juga mencakup komputasi citra medis.
Kimia
Cheminformatics adalah bidang yang berhubungan dengan analisis, pengolahan, dan penggunaan data kimia.
Robotika
Robotika dalam rekayasa informasi berfokus terutama pada algoritma dan program komputer yang digunakan untuk mengendalikan robot. Dengan demikian, rekayasa informasi cenderung lebih fokus pada robot otonom, mobile, atau probabilistik. Subbidang utama yang dipelajari oleh para insinyur informasi meliputi kontrol, persepsi, SLAM, dan perencanaan gerak.
Peralatan
Di masa lalu beberapa bidang dalam rekayasa informasi seperti pemrosesan sinyal menggunakan elektronik analog, tetapi saat ini sebagian besar rekayasa informasi dilakukan dengan komputer digital. Banyak tugas dalam rekayasa informasi dapat diparalelkan, sehingga saat ini rekayasa informasi dilakukan menggunakan CPU, GPU, dan akselerator AI. Di sana juga tertarik menggunakan komputer kuantum untuk beberapa subbidang teknik informasi seperti pembelajaran mesin dan robotika.
Sumber Artikel: en.wikipedia.org

Information Engineering
Data (komputasi)
Dipublikasikan oleh Viskha Dwi Marcella Nanda pada 17 Februari 2025
Dalam komputasi, data (diperlakukan sebagai tunggal, jamak, atau sebagai kata benda massa) adalah urutan dari satu atau lebih simbol; datum adalah simbol tunggal dari data. Data membutuhkan interpretasi untuk menjadi informasi. Data digital adalah data yang direpresentasikan menggunakan sistem bilangan biner satu (1) dan nol (0), bukan representasi analog. Dalam sistem komputer modern (pasca 1960), semua data adalah digital.
Data ada dalam tiga status: data saat istirahat, data dalam perjalanan, dan data yang digunakan. Data dalam komputer, dalam banyak kasus, bergerak sebagai data paralel. Data bergerak ke atau dari komputer, dalam banyak kasus, bergerak sebagai data serial. Data yang bersumber dari perangkat analog, seperti sensor suhu, dapat dikonversi ke digital menggunakan konverter analog-ke-digital. Data yang mewakili kuantitas, karakter, atau simbol yang operasinya dilakukan oleh komputer disimpan dan direkam pada media perekaman magnetik, optik, elektronik, atau mekanis, dan ditransmisikan dalam bentuk sinyal listrik atau optik digital. Data masuk dan keluar dari komputer melalui perangkat periferal.
Elemen memori komputer fisik terdiri dari alamat dan byte/word penyimpanan data. Data digital sering disimpan dalam database relasional, seperti tabel atau database SQL, dan umumnya dapat direpresentasikan sebagai pasangan kunci/nilai abstrak. Data dapat diatur dalam berbagai jenis struktur data, termasuk array, grafik, dan objek. Struktur data dapat menyimpan data dari berbagai jenis, termasuk angka, string, dan bahkan struktur data lainnya.
Karakteristik
Metadata membantu menerjemahkan data menjadi informasi. Metadata adalah data tentang data. Metadata mungkin tersirat, ditentukan atau diberikan.
Data yang berkaitan dengan peristiwa atau proses fisik akan memiliki komponen temporal. Komponen temporal ini mungkin tersirat. Ini adalah kasus ketika perangkat seperti pencatat suhu menerima data dari sensor suhu. Ketika suhu diterima, diasumsikan bahwa data memiliki referensi temporal sekarang. Jadi perangkat mencatat tanggal, waktu, dan suhu secara bersamaan. Saat pencatat data mengomunikasikan suhu, pencatat juga harus melaporkan tanggal dan waktu sebagai metadata untuk setiap pembacaan suhu.
Pada dasarnya, komputer mengikuti urutan instruksi yang diberikan dalam bentuk data. Serangkaian instruksi untuk melakukan tugas yang diberikan (atau tugas) disebut program. Program adalah data dalam bentuk instruksi berkode untuk mengendalikan pengoperasian komputer atau mesin lain. Dalam kasus nominal, program, seperti yang dijalankan oleh komputer, akan terdiri dari kode mesin. Elemen penyimpanan yang dimanipulasi oleh program, tetapi tidak benar-benar dijalankan oleh unit pemrosesan pusat (CPU), juga merupakan data. Pada dasarnya, satu datum adalah nilai yang disimpan di lokasi tertentu. Oleh karena itu, program komputer dimungkinkan untuk beroperasi pada program komputer lain, dengan memanipulasi data programnya.
Untuk menyimpan byte data dalam file, mereka harus serial dalam format file. Biasanya, program disimpan dalam jenis file khusus, berbeda dari yang digunakan untuk data lain. File yang dapat dieksekusi berisi program; semua file lain juga file data. Namun, file yang dapat dieksekusi juga dapat berisi data yang digunakan oleh program yang dibangun ke dalam program. Secara khusus, beberapa file yang dapat dieksekusi memiliki segmen data, yang secara nominal berisi konstanta dan nilai awal untuk variabel, yang keduanya dapat dianggap sebagai data.
Garis antara program dan data bisa menjadi kabur. Seorang juru bahasa, misalnya, adalah sebuah program. Data input ke juru bahasa itu sendiri adalah sebuah program, hanya saja bukan yang diekspresikan dalam bahasa mesin asli. Dalam banyak kasus, program yang ditafsirkan akan menjadi file teks yang dapat dibaca manusia, yang dimanipulasi dengan program editor teks. Metaprogramming juga melibatkan program yang memanipulasi program lain sebagai data. Program seperti compiler, linker, debugger, updater program, pemindai virus dan semacamnya menggunakan program lain sebagai data mereka.
Misalnya, pengguna mungkin terlebih dahulu menginstruksikan sistem operasi untuk memuat program pengolah kata dari satu file, dan kemudian menggunakan program yang sedang berjalan untuk membuka dan mengedit dokumen yang disimpan di file lain. Dalam contoh ini, dokumen akan dianggap sebagai data. Jika pengolah kata juga dilengkapi pemeriksa ejaan, maka kamus (daftar kata) untuk pemeriksa ejaan juga akan dianggap sebagai data. Algoritme yang digunakan oleh pemeriksa ejaan untuk menyarankan koreksi dapat berupa data kode mesin atau teks dalam beberapa bahasa pemrograman yang dapat diinterpretasikan.
Dalam penggunaan alternatif, file biner (yang tidak dapat dibaca manusia) kadang-kadang disebut data yang dibedakan dari teks yang dapat dibaca manusia.
Jumlah total data digital pada tahun 2007 diperkirakan mencapai 281 miliar gigabyte (281 exabytes).
Kunci dan nilai data, struktur dan persistensi
Kunci dalam data menyediakan konteks untuk nilai. Terlepas dari struktur data, selalu ada komponen kunci yang ada. Kunci dalam data dan struktur data sangat penting untuk memberi makna pada nilai data. Tanpa kunci yang langsung atau secara tidak langsung terkait dengan suatu nilai, atau kumpulan nilai dalam suatu struktur, nilai-nilai tersebut menjadi tidak berarti dan berhenti menjadi data. Artinya, harus ada komponen kunci yang terkait dengan komponen nilai agar dapat dianggap sebagai data.
Data dapat direpresentasikan dalam komputer dalam berbagai cara, seperti contoh berikut:
RAM
Memori akses acak (RAM) menyimpan data yang dapat diakses langsung oleh CPU. CPU hanya dapat memanipulasi data di dalam register atau memori prosesornya. Ini berbeda dengan penyimpanan data, di mana CPU harus mengarahkan transfer data antara perangkat penyimpanan (disk, tape...) dan memori. RAM adalah susunan lokasi linear yang berdekatan yang dapat dibaca atau ditulis oleh prosesor dengan memberikan alamat untuk operasi baca atau tulis. Prosesor dapat beroperasi di lokasi mana pun di memori kapan saja dalam urutan apa pun. Dalam RAM, elemen data terkecil adalah bit biner. Kemampuan dan keterbatasan mengakses RAM adalah khusus prosesor. Secara umum memori utama disusun sebagai array lokasi yang dimulai dari alamat 0 (heksadesimal 0). Setiap lokasi biasanya dapat menyimpan 8 atau 32 bit tergantung pada arsitektur komputer.
Kunci
Kunci data tidak harus berupa alamat perangkat keras langsung di memori. Kode kunci tidak langsung, abstrak dan logis dapat disimpan dalam hubungan dengan nilai-nilai untuk membentuk struktur data. Struktur data memiliki offset (atau tautan atau jalur) yang telah ditentukan sebelumnya dari awal struktur, di mana nilai data disimpan. Oleh karena itu, kunci data terdiri dari kunci struktur ditambah offset (atau tautan atau jalur) ke dalam struktur. Ketika struktur seperti itu diulang, menyimpan variasi nilai data dan kunci data dalam struktur berulang yang sama, hasilnya dapat dianggap menyerupai tabel, di mana setiap elemen dari struktur berulang dianggap sebagai kolom dan setiap pengulangan struktur dianggap sebagai deretan tabel. Dalam organisasi data seperti itu, kunci data biasanya berupa nilai dalam satu (atau gabungan nilai dalam beberapa) kolom.
Struktur data berulang yang terorganisir
Tampilan tabular dari struktur data yang berulang hanyalah salah satu dari banyak kemungkinan. Struktur data yang berulang dapat diatur secara hierarkis, sehingga node dihubungkan satu sama lain dalam rangkaian hubungan induk-anak. Nilai dan struktur data yang berpotensi lebih kompleks terkait dengan node. Dengan demikian hierarki nodal menyediakan kunci untuk menangani struktur data yang terkait dengan node. Representasi ini dapat dianggap sebagai pohon terbalik. Misalnya. sistem file sistem operasi komputer modern adalah contoh umum; dan XML adalah yang lain.
Data yang diurutkan atau diurutkan
Data memiliki beberapa fitur yang melekat ketika diurutkan pada kunci. Semua nilai untuk subset kunci muncul bersamaan. Saat melewati secara berurutan melalui grup data dengan kunci yang sama, atau subset dari perubahan kunci, ini disebut dalam lingkaran pemrosesan data sebagai pemutusan, atau pemutusan kontrol. Ini terutama memfasilitasi agregasi nilai data pada himpunan bagian dari kunci.
Penyimpanan periferal
Sampai munculnya memori non-volatil massal seperti flash, penyimpanan data persisten secara tradisional dicapai dengan menulis data ke perangkat blok eksternal seperti pita magnetik dan drive disk. Perangkat ini biasanya mencari lokasi pada media magnetik dan kemudian membaca atau menulis blok data dengan ukuran yang telah ditentukan. Dalam hal ini, lokasi pencarian pada media adalah kunci data dan blok adalah nilai data. Sistem file data disk mentah yang digunakan awal atau sistem operasi disk mencadangkan blok bersebelahan pada drive disk untuk file data. Dalam sistem tersebut, file dapat diisi, kehabisan ruang data sebelum semua data dituliskan kepada mereka. Jadi banyak ruang data yang tidak terpakai dicadangkan secara tidak produktif untuk memastikan ruang kosong yang memadai untuk setiap file. Kemudian sistem file memperkenalkan partisi. Mereka memesan blok ruang data disk untuk partisi dan menggunakan blok yang dialokasikan secara lebih ekonomis, dengan menetapkan blok partisi secara dinamis ke file sesuai kebutuhan. Untuk mencapai ini, sistem file harus melacak blok mana yang digunakan atau tidak digunakan oleh file data dalam katalog atau tabel alokasi file. Meskipun ini memanfaatkan ruang data disk dengan lebih baik, hal itu mengakibatkan fragmentasi file di seluruh disk, dan peningkatan kinerja yang bersamaan karena waktu pencarian tambahan untuk membaca data. Sistem file modern mengatur ulang file yang terfragmentasi secara dinamis untuk mengoptimalkan waktu akses file. Perkembangan lebih lanjut dalam sistem file menghasilkan virtualisasi disk drive yaitu di mana drive logis dapat didefinisikan sebagai partisi dari sejumlah drive fisik.
Data yang diindeks
Mengambil subset kecil data dari set yang jauh lebih besar mungkin menyiratkan pencarian yang tidak efisien melalui data secara berurutan. Indeks adalah cara untuk menyalin kunci dan alamat lokasi dari struktur data dalam file, tabel dan kumpulan data, kemudian mengaturnya menggunakan struktur pohon terbalik untuk mengurangi waktu yang dibutuhkan untuk mengambil subset dari data asli. untuk melakukan ini, kunci dari subset data yang akan diambil harus diketahui sebelum pengambilan dimulai. Indeks yang paling populer adalah B-tree dan metode pengindeksan kunci hash dinamis. Pengindeksan adalah overhead untuk pengarsipan dan pengambilan data. Ada cara lain untuk mengatur indeks, mis. menyortir kunci dan menggunakan algoritma pencarian biner.
Abstraksi dan tipuan
Pemrograman berorientasi objek menggunakan dua konsep dasar untuk memahami data dan perangkat lunak:
- Struktur peringkat taksonomi kelas, yang merupakan contoh struktur data hierarkis; dan
- pada saat dijalankan, pembuatan referensi ke struktur data dalam memori dari objek yang telah dibuat instancenya dari perpustakaan kelas.
Hanya setelah instantiasi objek dari kelas tertentu ada. Setelah referensi objek dihapus, objek juga tidak ada lagi. Lokasi memori tempat data objek disimpan adalah sampah dan diklasifikasi ulang sebagai memori tidak terpakai yang tersedia untuk digunakan kembali.
Databasis data
Munculnya database memperkenalkan lapisan abstraksi lebih lanjut untuk penyimpanan data persisten. Basis data menggunakan metadata, dan protokol bahasa kueri terstruktur antara sistem klien dan server, berkomunikasi melalui jaringan komputer, menggunakan sistem pencatatan komit dua fase untuk memastikan kelengkapan transaksi, saat menyimpan data.
Pemrosesan data terdistribusi paralel
Teknologi persistensi data modern yang skalabel dan berkinerja tinggi, seperti Apache Hadoop, bergantung pada pemrosesan data paralel yang didistribusikan secara masif di banyak komputer komoditas pada jaringan bandwidth tinggi. Dalam sistem seperti itu, data didistribusikan di beberapa komputer dan oleh karena itu setiap komputer tertentu dalam sistem harus diwakili dalam kunci data, baik secara langsung, atau tidak langsung. Hal ini memungkinkan diferensiasi antara dua set data yang identik, masing-masing diproses pada komputer yang berbeda pada waktu yang sama.
Sumber Artikel: en.wikipedia.org

Information Engineering
Pengolahan data
Dipublikasikan oleh Viskha Dwi Marcella Nanda pada 17 Februari 2025
Pengolahan data adalah pengumpulan dan manipulasi data untuk menghasilkan informasi yang berarti. Pemrosesan data adalah suatu bentuk pemrosesan informasi, yaitu modifikasi (pengolahan) informasi dengan cara apa pun yang dapat dideteksi oleh pengamat.
Istilah "Pemrosesan Data", atau "DP" juga telah digunakan untuk merujuk ke departemen dalam organisasi yang bertanggung jawab atas pengoperasian program pemrosesan data.
Fungsi pemrosesan data
Pemrosesan data dapat melibatkan berbagai proses, termasuk:
- Validasi – Memastikan bahwa data yang diberikan benar dan relevan.
- Sorting – "mengatur item dalam beberapa urutan dan/atau dalam set yang berbeda."
- Peringkasan (statistik) atau (otomatis) – mengurangi data terperinci ke poin utamanya.
- Agregasi – menggabungkan beberapa bagian data.
- Analisis – "pengumpulan, pengorganisasian, analisis, interpretasi, dan penyajian data."
- Pelaporan – daftar detail atau ringkasan data atau informasi yang dihitung.
- Klasifikasi – pemisahan data ke dalam berbagai kategori.
Sejarah
Sejarah Biro Sensus Amerika Serikat menggambarkan evolusi pengolahan data dari manual melalui prosedur elektronik.
Pemrosesan data manual
Meskipun penggunaan istilah pemrosesan data secara luas baru dimulai pada tahun 1950-an, fungsi pemrosesan data telah dilakukan secara manual selama ribuan tahun. Misalnya, pembukuan melibatkan fungsi-fungsi seperti memposting transaksi dan menghasilkan laporan seperti neraca dan laporan arus kas. Metode yang sepenuhnya manual ditambah dengan aplikasi kalkulator mekanik atau elektronik. Seseorang yang tugasnya melakukan perhitungan secara manual atau menggunakan kalkulator disebut "komputer".
Jadwal Sensus Amerika Serikat tahun 1890 adalah yang pertama mengumpulkan data berdasarkan individu daripada rumah tangga. Sejumlah pertanyaan dapat dijawab dengan memberi tanda centang pada kotak yang sesuai pada formulir. Dari tahun 1850 hingga 1880 Biro Sensus menggunakan "sistem penghitungan, yang karena semakin banyaknya kombinasi klasifikasi yang diperlukan, menjadi semakin kompleks. Hanya sejumlah kombinasi yang dapat dicatat dalam satu penghitungan, sehingga perlu untuk menangani jadwal 5 atau 6 kali, untuk penghitungan independen sebanyak. "Butuh waktu lebih dari 7 tahun untuk mempublikasikan hasil sensus 1880" menggunakan metode pemrosesan manual.
Pemrosesan data otomatis
Istilah pemrosesan data otomatis diterapkan pada operasi yang dilakukan dengan menggunakan peralatan perekam unit, seperti penerapan peralatan kartu berlubang oleh Herman Hollerith untuk Sensus Amerika Serikat tahun 1890. "Dengan menggunakan peralatan punchcard Hollerith, Kantor Sensus mampu menyelesaikan tabulasi sebagian besar data sensus 1890 dalam 2 hingga 3 tahun, dibandingkan dengan 7 hingga 8 tahun untuk sensus 1880. Diperkirakan bahwa menggunakan sistem Hollerith menghemat sekitar $5 juta dalam pemrosesan biaya" pada tahun 1890 dolar meskipun ada dua kali lebih banyak pertanyaan seperti pada tahun 1880.
Pemrosesan data elektronik
Pemrosesan data terkomputerisasi, atau Pemrosesan data elektronik mewakili perkembangan selanjutnya, dengan komputer yang digunakan sebagai pengganti beberapa peralatan independen. Biro Sensus pertama kali menggunakan komputer elektronik secara terbatas untuk Sensus Amerika Serikat 1950, menggunakan sistem UNIVAC I, disampaikan pada tahun 1952.
Perkembangan lainnya
Istilah pemrosesan data sebagian besar telah dimasukkan ke dalam istilah teknologi informasi (TI) yang lebih umum. Istilah "pemrosesan data" yang lebih lama menunjukkan teknologi yang lebih tua. Misalnya, pada tahun 1996 Asosiasi Pengelola Pemrosesan Data (DPMA) berubah nama menjadi Asosiasi Profesional Teknologi Informasi." Meskipun demikian, istilah-istilah tersebut kurang lebih sama.
Aplikasi
Pemrosesan data komersial
Pemrosesan data komersial melibatkan sejumlah besar data input, operasi komputasi yang relatif sedikit, dan volume output yang besar. Misalnya, perusahaan asuransi perlu menyimpan catatan tentang puluhan atau ratusan ribu polis, tagihan cetak dan pos, serta penerimaan dan pembayaran pos.
Analisis data
Dalam sains dan teknik, istilah pemrosesan data dan sistem informasi dianggap terlalu luas, dan istilah pemrosesan data biasanya digunakan untuk tahap awal yang diikuti dengan analisis data pada tahap kedua dari penanganan data secara keseluruhan.
Analisis data menggunakan algoritme khusus dan perhitungan statistik yang jarang diamati dalam lingkungan bisnis umum yang khas. Untuk analisis data, suite perangkat lunak seperti SPSS atau SAS, atau perangkat lunak gratis seperti DAP, gretl atau PSPP sering digunakan.
Sumber Artikel: en.wikipedia.org

Information Engineering
Desain Basisdata
Dipublikasikan oleh Viskha Dwi Marcella Nanda pada 17 Februari 2025
Desain basisdata adalah organisasi data menurut model database. Perancang menentukan data apa yang harus disimpan dan bagaimana elemen data saling berhubungan. Dengan informasi ini, mereka dapat mulai menyesuaikan data dengan model database. Sistem manajemen basis data mengelola data yang sesuai.
Desain basis data melibatkan pengklasifikasian data dan pengidentifikasian hubungan timbal balik. Representasi teoritis dari data ini disebut ontologi. Ontologi adalah teori di balik desain database.
Menentukan data yang akan disimpan
Dalam sebagian besar kasus, orang yang melakukan desain database adalah orang dengan keahlian di bidang desain database, bukan keahlian dalam domain dari mana data yang akan disimpan diambil mis. informasi keuangan, informasi biologis, dll. Oleh karena itu, data yang akan disimpan dalam database harus ditentukan melalui kerja sama dengan orang yang memang memiliki keahlian dalam domain tersebut, dan siapa yang mengetahui data apa yang harus disimpan dalam sistem.
Proses ini adalah salah satu yang umumnya dianggap sebagai bagian dari analisis kebutuhan, dan membutuhkan keterampilan dari desainer database untuk memperoleh informasi yang dibutuhkan dari mereka yang memiliki pengetahuan domain. Ini karena mereka yang memiliki pengetahuan domain yang diperlukan seringkali tidak dapat mengungkapkan dengan jelas apa persyaratan sistem mereka untuk database karena mereka tidak terbiasa berpikir dalam hal elemen data diskrit yang harus disimpan. Data yang akan disimpan dapat ditentukan dengan Spesifikasi Kebutuhan.
Menentukan hubungan data
Setelah perancang basis data mengetahui data yang akan disimpan di dalam basis data, mereka kemudian harus menentukan di mana ketergantungan berada di dalam data. Terkadang ketika data diubah, Anda dapat mengubah data lain yang tidak terlihat. Misalnya, dalam daftar nama dan alamat, dengan asumsi situasi di mana beberapa orang dapat memiliki alamat yang sama, tetapi satu orang tidak dapat memiliki lebih dari satu alamat, alamat tergantung pada nama. Ketika diberikan nama dan daftar alamat dapat ditentukan secara unik; namun, kebalikannya tidak berlaku - ketika diberi alamat dan daftar, nama tidak dapat ditentukan secara unik karena banyak orang dapat tinggal di sebuah alamat. Karena sebuah alamat ditentukan oleh sebuah nama, sebuah alamat dianggap bergantung pada sebuah nama.
(CATATAN: Kesalahpahaman yang umum adalah bahwa model relasional disebut demikian karena menyatakan hubungan antara elemen data di dalamnya. Ini tidak benar. Model relasional dinamakan demikian karena didasarkan pada struktur matematika yang dikenal sebagai hubungan.)
Menyusun data secara logis
Setelah hubungan dan ketergantungan di antara berbagai bagian informasi telah ditentukan, dimungkinkan untuk mengatur data ke dalam struktur logis yang kemudian dapat dipetakan ke dalam objek penyimpanan yang didukung oleh sistem manajemen basis data. Dalam kasus database relasional, objek penyimpanan adalah tabel yang menyimpan data dalam baris dan kolom. Dalam database Object, objek penyimpanan berhubungan langsung dengan objek yang digunakan oleh bahasa pemrograman berorientasi objek yang digunakan untuk menulis aplikasi yang akan mengelola dan mengakses data. Hubungan dapat didefinisikan sebagai atribut dari kelas objek yang terlibat atau sebagai metode yang beroperasi pada kelas objek.
Cara pemetaan ini umumnya dilakukan sedemikian rupa sehingga setiap kumpulan data terkait yang bergantung pada satu objek, apakah nyata atau abstrak, ditempatkan dalam sebuah tabel. Hubungan antara objek-objek dependen ini kemudian disimpan sebagai link antara berbagai objek.
Setiap tabel dapat mewakili implementasi dari objek logis atau hubungan yang menggabungkan satu atau lebih instance dari satu atau lebih objek logis. Hubungan antar tabel kemudian dapat disimpan sebagai tautan yang menghubungkan tabel anak dengan orang tua. Karena hubungan logis yang kompleks itu sendiri adalah tabel, mereka mungkin akan memiliki tautan ke lebih dari satu induk.
Diagram ER (model hubungan entitas)
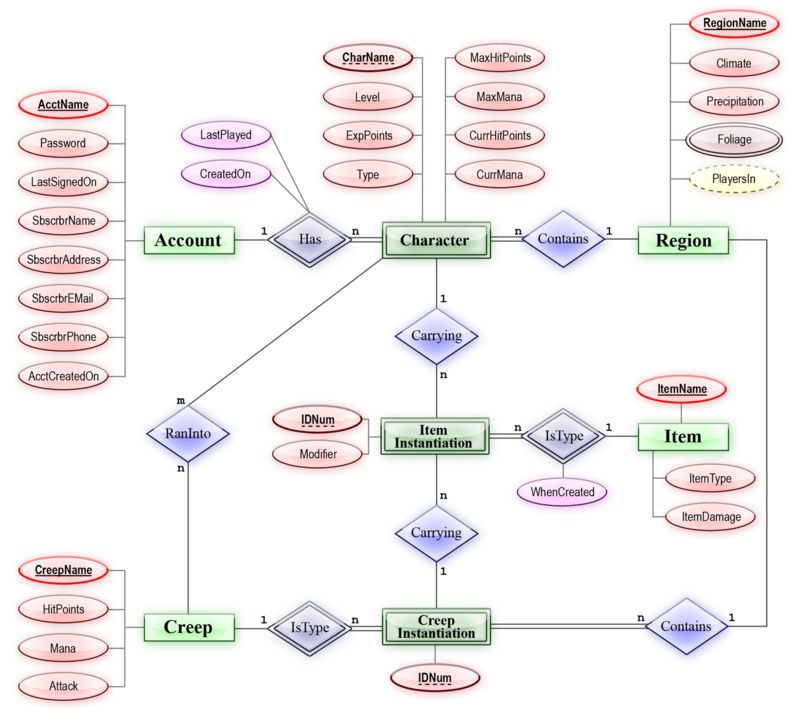
Contoh diagram Entity-relationship
Desain database juga menyertakan diagram ER (entity-relationship model). Diagram ER adalah diagram yang membantu merancang database dengan cara yang efisien.
Atribut dalam diagram ER biasanya dimodelkan sebagai oval dengan nama atribut, dihubungkan dengan entitas atau relasi yang memuat atribut tersebut.
Model ER umumnya digunakan dalam desain sistem informasi; misalnya, mereka digunakan untuk menggambarkan kebutuhan informasi dan/atau jenis informasi yang akan disimpan dalam database selama fase desain struktur konseptual.[3]
Saran proses desain untuk Microsoft Access
Tentukan tujuan database - Ini membantu mempersiapkan langkah-langkah selanjutnya.
Temukan dan atur informasi yang diperlukan - Kumpulkan semua jenis informasi untuk dicatat dalam database, seperti nama produk dan nomor pesanan.
Bagi informasi ke dalam tabel - Bagi item informasi menjadi entitas atau subjek utama, seperti Produk atau Pesanan. setiap mata pelajaran kemudian menjadi sebuah tabel.
Ubah item informasi menjadi kolom - Putuskan informasi apa yang perlu disimpan di setiap tabel. Setiap item menjadi bidang, dan ditampilkan sebagai kolom dalam tabel. Misalnya, tabel Karyawan mungkin menyertakan bidang seperti Nama Belakang dan Tanggal Sewa.
Tentukan kunci utama - Pilih kunci utama setiap tabel. Kunci utama adalah kolom, atau kumpulan kolom, yang digunakan untuk mengidentifikasi setiap baris secara unik. Contohnya mungkin ID Produk atau ID Pesanan.
Mengatur hubungan tabel - Lihat setiap tabel dan putuskan bagaimana data dalam satu tabel terkait dengan data di tabel lain. Tambahkan bidang ke tabel atau buat tabel baru untuk memperjelas hubungan, jika perlu.
Perbaiki desain - Analisis desain untuk kesalahan. Buat tabel dan tambahkan beberapa catatan data sampel. Periksa apakah hasil datang dari tabel seperti yang diharapkan. Lakukan penyesuaian pada desain, sesuai kebutuhan.
Terapkan aturan normalisasi - Terapkan aturan normalisasi data untuk melihat apakah tabel terstruktur dengan benar. Buat penyesuaian pada tabel, sesuai kebutuhan.
Normalisasi
Di bidang desain basis data relasional, normalisasi adalah cara sistematis untuk memastikan bahwa struktur basis data cocok untuk kueri tujuan umum dan bebas dari karakteristik tertentu yang tidak diinginkan—anomali penyisipan, pembaruan, dan penghapusan yang dapat menyebabkan hilangnya integritas data.
Bagian standar dari panduan desain database adalah bahwa desainer harus membuat desain yang sepenuhnya dinormalisasi; denormalisasi selektif selanjutnya dapat dilakukan, tetapi hanya untuk alasan kinerja. Trade-off adalah ruang penyimpanan vs kinerja. Semakin dinormalisasi desainnya, semakin sedikit redundansi data yang ada (dan oleh karena itu, dibutuhkan lebih sedikit ruang untuk disimpan), namun, pola pengambilan data umum sekarang mungkin memerlukan penggabungan, penggabungan, dan pengurutan yang kompleks untuk terjadi - yang memakan lebih banyak data membaca, dan menghitung siklus. Beberapa disiplin pemodelan, seperti pendekatan pemodelan dimensi untuk desain gudang data, secara eksplisit merekomendasikan desain yang tidak dinormalisasi, yaitu desain yang sebagian besar tidak mematuhi 3NF. Normalisasi terdiri dari bentuk normal yaitu 1NF,2NF,3NF,BOYCE-CODD NF (3.5NF),4NF dan 5NF
Database dokumen mengambil pendekatan yang berbeda. Sebuah dokumen yang disimpan dalam database seperti itu, biasanya akan berisi lebih dari satu unit data yang dinormalisasi dan seringkali juga hubungan antar unit. Jika semua unit data dan hubungan yang bersangkutan sering diambil bersama-sama, maka pendekatan ini mengoptimalkan jumlah pengambilan. Ini juga menyederhanakan bagaimana data direplikasi, karena sekarang ada unit data yang dapat diidentifikasi dengan jelas yang konsistensinya mandiri. Pertimbangan lain adalah bahwa membaca dan menulis satu dokumen dalam database tersebut akan memerlukan satu transaksi - yang dapat menjadi pertimbangan penting dalam arsitektur Microservices. Dalam situasi seperti itu, seringkali, sebagian dokumen diambil dari layanan lain melalui API dan disimpan secara lokal untuk alasan efisiensi. Jika unit data akan dibagi di seluruh layanan, maka membaca (atau menulis) untuk mendukung konsumen layanan mungkin memerlukan lebih dari satu panggilan layanan, dan ini dapat mengakibatkan pengelolaan beberapa transaksi, yang mungkin tidak disukai.
Skema konseptual
Desain fisik
Desain fisik database menentukan konfigurasi fisik database pada media penyimpanan. Ini termasuk spesifikasi rinci elemen data, tipe data, opsi pengindeksan dan parameter lain yang berada dalam kamus data DBMS. Ini adalah desain rinci dari sebuah sistem yang mencakup modul & spesifikasi hardware & software database dari sistem. Beberapa aspek yang dibahas pada lapisan fisik:
- Keamanan - pengguna akhir, serta keamanan administratif.
- Replikasi - bagian data apa yang disalin ke database lain, dan seberapa sering. Apakah ada banyak master, atau satu?
- Ketersediaan tinggi - apakah konfigurasi aktif-pasif, atau aktif-aktif, topologi, skema koordinasi, target keandalan, dll semua harus ditentukan.
- Partisi - jika database didistribusikan, maka untuk satu entitas, bagaimana data didistribusikan di antara semua partisi database, dan bagaimana kegagalan partisi diperhitungkan.
- Skema pencadangan dan pemulihan.
Pada tingkat aplikasi, aspek lain dari desain fisik dapat mencakup kebutuhan untuk mendefinisikan prosedur tersimpan, atau tampilan kueri yang terwujud, kubus OLAP, dll.
Sumber Artikel: en.wikipedia.org

Information Engineering
Sistem Manajemen Informasi
Dipublikasikan oleh Viskha Dwi Marcella Nanda pada 17 Februari 2025
Sistem informasi manajemen atau management information system (MIS) adalah sistem informasi yang digunakan untuk pengambilan keputusan, dan untuk koordinasi, kontrol, analisis, dan visualisasi informasi dalam suatu organisasi. Studi tentang sistem informasi manajemen melibatkan orang, proses dan teknologi dalam konteks organisasi.
Dalam pengaturan perusahaan, tujuan akhir dari penggunaan sistem informasi manajemen adalah untuk meningkatkan nilai dan keuntungan bisnis.
Sejarah
Meskipun dapat diperdebatkan bahwa sejarah sistem informasi manajemen sudah ada sejak perusahaan menggunakan buku besar untuk melacak akuntansi, sejarah modern MIS dapat dibagi menjadi lima era yang awalnya diidentifikasi oleh Kenneth C. Laudon dan Jane Laudon dalam mani mereka. buku ajar Sistem Informasi Manajemen.
- Era Pertama – Komputer mainframe dan komputer mini
- Era Kedua – Komputer pribadi
- Era Ketiga – Jaringan klien/server
- Era Keempat – Komputasi perusahaan
- Era Kelima – Komputasi awan
Era pertama (komputer mainframe dan komputer mini) diperintah oleh IBM dan komputer mainframe mereka yang menyediakan perangkat keras dan perangkat lunak. Komputer-komputer ini sering menempati seluruh ruangan dan membutuhkan tim untuk menjalankannya. Sebagai teknologi maju, komputer ini mampu menangani kapasitas yang lebih besar dan karena itu mengurangi biaya mereka. Komputer mini yang lebih kecil dan lebih terjangkau memungkinkan bisnis yang lebih besar untuk menjalankan pusat komputasi mereka sendiri di rumah / di tempat / di tempat.
Era kedua (komputer pribadi) dimulai pada tahun 1965 ketika mikroprosesor mulai bersaing dengan mainframe dan komputer mini dan mempercepat proses desentralisasi daya komputasi dari pusat data besar ke kantor yang lebih kecil. Pada akhir 1970-an, teknologi komputer mini memberi jalan kepada komputer pribadi dan komputer yang relatif murah menjadi komoditas pasar massal, memungkinkan bisnis untuk memberikan akses kepada karyawan mereka ke daya komputasi yang sepuluh tahun sebelumnya akan menelan biaya puluhan ribu dolar. Proliferasi komputer ini menciptakan pasar yang siap untuk interkoneksi jaringan dan mempopulerkan Internet. (Mikroprosesor pertama — perangkat empat bit yang ditujukan untuk kalkulator yang dapat diprogram — diperkenalkan pada tahun 1971, dan sistem berbasis mikroprosesor tidak tersedia selama beberapa tahun. MITS Altair 8800 adalah sistem berbasis mikroprosesor pertama yang umum dikenal, diikuti dengan cermat oleh Apple I dan II. Dapat diperdebatkan bahwa sistem berbasis mikroprosesor tidak membuat terobosan signifikan dalam penggunaan komputer mini sampai tahun 1979, ketika VisiCalc mendorong rekor penjualan Apple II yang dijalankannya. IBM PC yang diperkenalkan pada tahun 1981 lebih luas cocok untuk bisnis, tetapi keterbatasannya membatasi kemampuannya untuk menantang sistem komputer mini hingga mungkin akhir 1980-an hingga awal 1990-an.)
Era ketiga (jaringan klien/server) muncul ketika kompleksitas teknologi meningkat, biaya menurun, dan pengguna akhir (sekarang karyawan biasa) membutuhkan sistem untuk berbagi informasi dengan karyawan lain dalam suatu perusahaan. Komputer di jaringan umum berbagi informasi di server. Hal ini memungkinkan ribuan bahkan jutaan orang mengakses data secara bersamaan di jaringan yang disebut sebagai Intranet.
Era keempat (komputasi perusahaan) yang dimungkinkan oleh jaringan berkecepatan tinggi, mengkonsolidasikan aplikasi perangkat lunak khusus departemen asli ke dalam platform perangkat lunak terintegrasi yang disebut sebagai perangkat lunak perusahaan. Platform baru ini mengikat semua aspek perusahaan bisnis bersama-sama menawarkan akses informasi yang kaya yang mencakup struktur manajemen yang lengkap.
Teknologi
Istilah sistem informasi manajemen (SIM), sistem manajemen informasi (IMS), sistem informasi (IS), perencanaan sumber daya perusahaan (ERP), ilmu komputer, teknik komputer listrik, dan manajemen teknologi informasi (TI) sering membingungkan. MIS adalah bagian hierarki dari sistem informasi. MIS lebih berfokus pada organisasi yang mempersempit pemanfaatan teknologi informasi untuk meningkatkan nilai bisnis. Ilmu komputer lebih berfokus pada perangkat lunak dengan aplikasi yang dapat digunakan dalam MIS.[9] Teknik komputer listrik berfokus pada produk terutama berurusan dengan arsitektur perangkat keras di belakang sistem komputer. Perangkat lunak ERP adalah bagian dari MIS dan manajemen TI mengacu pada manajemen teknis departemen TI yang mungkin mencakup MIS.
Karir di MIS berfokus pada pemahaman dan memproyeksikan penggunaan praktis dari sistem informasi manajemen. Ini mempelajari interaksi, organisasi dan proses antara teknologi, orang dan informasi untuk memecahkan masalah.
Pengelolaan
Sementara sistem informasi manajemen dapat digunakan oleh setiap dan setiap tingkat manajemen, keputusan sistem mana yang akan diterapkan umumnya jatuh pada chief information officer (CIO) dan chief technology officer (CTO). Petugas ini umumnya bertanggung jawab atas strategi teknologi keseluruhan organisasi termasuk mengevaluasi bagaimana teknologi baru dapat membantu organisasi mereka. Mereka bertindak sebagai pengambil keputusan dalam proses implementasi SIM baru.
Setelah keputusan dibuat, direktur TI, termasuk direktur MIS, bertanggung jawab atas implementasi teknis sistem. Mereka juga bertanggung jawab untuk menerapkan kebijakan yang mempengaruhi MIS (baik kebijakan spesifik baru yang diturunkan oleh CIO atau CTO atau kebijakan yang menyelaraskan sistem baru dengan kebijakan TI organisasi secara keseluruhan). Mereka juga berperan untuk memastikan ketersediaan data dan layanan jaringan serta keamanan data yang terlibat dengan mengkoordinasikan kegiatan TI.
Setelah implementasi, pengguna yang ditugaskan akan memiliki akses yang sesuai ke informasi yang relevan. Penting untuk dicatat bahwa tidak semua orang yang memasukkan data ke dalam SIM harus berada di level manajemen. Merupakan praktik umum untuk memasukkan input ke MIS oleh karyawan non-manajerial meskipun mereka jarang memiliki akses ke laporan dan platform pendukung keputusan yang ditawarkan oleh sistem ini.
Jenis
Berikut ini adalah jenis sistem informasi yang digunakan untuk membuat laporan, mengekstrak data, dan membantu dalam proses pengambilan keputusan manajer tingkat menengah dan operasional.
- Sistem pendukung keputusan (SPK) adalah aplikasi program komputer yang digunakan oleh manajemen menengah dan atas untuk mengumpulkan informasi dari berbagai sumber untuk mendukung pemecahan masalah dan pengambilan keputusan. Sebuah DSS digunakan sebagian besar untuk masalah keputusan semi-terstruktur dan tidak terstruktur.
- Sistem informasi eksekutif (EIS) adalah alat pelaporan yang menyediakan akses cepat ke laporan ringkasan yang berasal dari semua tingkat dan departemen perusahaan seperti akuntansi, sumber daya manusia, dan operasi.
- Sistem informasi pemasaran adalah Sistem Informasi manajemen yang dirancang khusus untuk mengelola aspek pemasaran bisnis.
- Sistem informasi akuntansi berfokus pada fungsi akuntansi.
- Sistem manajemen sumber daya manusia digunakan untuk aspek personalia.
- Sistem otomatisasi kantor (OAS) mendukung komunikasi dan produktivitas di perusahaan dengan mengotomatiskan alur kerja dan menghilangkan kemacetan. OAS dapat diterapkan pada setiap dan semua tingkat manajemen.
- Sistem Manajemen Informasi Sekolah (SIMS) mencakup administrasi sekolah, sering kali termasuk materi pengajaran dan pembelajaran.
- Perangkat lunak perencanaan sumber daya perusahaan (ERP) memfasilitasi aliran informasi antara semua fungsi bisnis di dalam batas-batas organisasi dan mengelola koneksi ke pemangku kepentingan luar.
- Basis data lokal, dapat berupa alat kecil yang disederhanakan untuk manajer dan dianggap sebagai versi tingkat dasar atau dasar dari MIS.
Keuntungan dan kerugian
Berikut ini adalah beberapa manfaat yang dapat diperoleh dengan menggunakan MIS:
- Meningkatkan efisiensi operasional organisasi, menambah nilai produk yang ada, melahirkan inovasi dan pengembangan produk baru, dan membantu manajer membuat keputusan yang lebih baik.
- Perusahaan dapat mengidentifikasi kekuatan dan kelemahan mereka karena adanya laporan pendapatan, catatan kinerja karyawan, dll. Mengidentifikasi aspek-aspek ini dapat membantu perusahaan meningkatkan proses bisnis dan operasinya.
- Ketersediaan data pelanggan dan umpan balik dapat membantu perusahaan untuk menyelaraskan proses bisnisnya sesuai dengan kebutuhan pelanggannya. Pengelolaan data pelanggan yang efektif dapat membantu perusahaan untuk melakukan kegiatan pemasaran dan promosi secara langsung.
- MIS dapat membantu perusahaan mendapatkan keunggulan kompetitif.
- Laporan MIS dapat membantu pengambilan keputusan serta mengurangi waktu henti untuk item yang dapat ditindaklanjuti.
Beberapa kelemahan sistem MIS:
- Pengambilan dan penyebaran tergantung pada perangkat keras dan perangkat lunak teknologi.
- Potensi informasi yang tidak akurat.
Aplikasi perusahaan
Sistem perusahaan—juga dikenal sebagai sistem perencanaan sumber daya perusahaan (ERP)—menyediakan modul perangkat lunak terintegrasi dan database terpadu yang digunakan personel untuk merencanakan, mengelola, dan mengontrol proses bisnis inti di berbagai lokasi. Modul sistem ERP dapat mencakup keuangan, akuntansi, pemasaran, sumber daya manusia, produksi, manajemen inventaris, dan distribusi.
Sistem manajemen rantai pasokan (SCM) memungkinkan manajemen rantai pasokan yang lebih efisien dengan mengintegrasikan tautan dalam rantai pasokan. Ini mungkin termasuk pemasok, produsen, grosir, pengecer, dan pelanggan akhir.
Sistem manajemen hubungan pelanggan (CRM) membantu bisnis mengelola hubungan dengan pelanggan potensial dan saat ini serta mitra bisnis di seluruh pemasaran, penjualan, dan layanan.
Sistem manajemen pengetahuan (KMS) membantu organisasi memfasilitasi pengumpulan, pencatatan, pengorganisasian, pengambilan, dan penyebaran pengetahuan. Ini mungkin termasuk dokumen, catatan akuntansi, prosedur, praktik, dan keterampilan yang tidak tercatat. Manajemen pengetahuan (KM) sebagai suatu sistem mencakup proses penciptaan dan perolehan pengetahuan dari proses internal dan dunia eksternal. Pengetahuan yang terkumpul dimasukkan ke dalam kebijakan dan prosedur organisasi, dan kemudian disebarluaskan kepada para pemangku kepentingan.
Sumber Artikel: en.wikipedia.org

Information Engineering
Kecerdasan Buatan
Dipublikasikan oleh Viskha Dwi Marcella Nanda pada 17 Februari 2025
Kecerdasan buatan adalah kecerdasan yang ditambahkan kepada suatu sistem yang bisa diatur dalam konteks ilmiah atau bisa disebut juga intelegensi artifisial (bahasa Inggris: artificial intelligence) atau hanya disingkat AI, didefinisikan sebagai kecerdasan entitas ilmiah. Andreas Kaplan dan Michael Haenlein mendefinisikan kecerdasan buatan sebagai “kemampuan sistem untuk menafsirkan data eksternal dengan benar, untuk belajar dari data tersebut, dan menggunakan pembelajaran tersebut guna mencapai tujuan dan tugas tertentu melalui adaptasi yang fleksibel”. Sistem seperti ini umumnya dianggap komputer. Kecerdasan diciptakan dan dimasukkan ke dalam komputer agar dapat melakukan pekerjaan seperti yang dapat dilakukan manusia. Beberapa macam bidang yang menggunakan kecerdasan buatan antara lain sistem pakar, permainan komputer, logika kabur, jaringan saraf tiruan dan robotika. Secara teknis, kecerdasan buatan adalah model statistik yang digunakan untuk mengambil keputusan dengan menggeneralisir karakteristik dari suatu objek berbasis data yang kemudian dipasang di berbagai perangkat elektronik.
Banyak hal yang kelihatannya sulit untuk kecerdasan manusia, tetapi untuk informatika relatif tidak bermasalah. Seperti contoh: mentransformasikan persamaan, menyelesaikan persamaan integral, atau membuat permainan catur. Di sisi lain, hal yang bagi manusia kelihatannya menuntut sedikit kecerdasan, sampai sekarang masih sulit untuk direalisasikan dalam Informatika. Seperti contoh: Pengenalan Objek/Muka, bermain sepak bola.
Walaupun AI memiliki konotasi fiksi ilmiah yang kuat, AI membentuk cabang yang sangat penting pada ilmu komputer, berhubungan dengan perilaku, pembelajaran dan adaptasi yang cerdas dalam sebuah mesin. Penelitian dalam AI menyangkut pembuatan mesin dan program komputer untuk mengotomatisasikan tugas-tugas yang membutuhkan perilaku cerdas. Termasuk contohnya adalah pengendalian, perencanaan dan penjadwalan, kemampuan untuk menjawab diagnosa dan pertanyaan pelanggan, serta pengenalan tulisan tangan, suara dan wajah. Hal-hal seperti itu telah menjadi disiplin ilmu tersendiri, yang memusatkan perhatian pada penyediaan solusi masalah kehidupan yang nyata. Sistem AI sekarang ini sering digunakan dalam bidang ekonomi, sains, obat-obatan, teknik dan militer, seperti yang telah dibangun dalam beberapa aplikasi perangkat lunak komputer rumah dan video game.
Kecerdasan buatan ini bukan hanya ingin mengerti apa itu sistem kecerdasan, tetapi juga mengkonstruksinya.
Tidak ada definisi yang memuaskan untuk 'kecerdasan':
kecerdasan: kemampuan untuk memperoleh pengetahuan dan menggunakannya
atau kecerdasan yaitu apa yang diukur oleh sebuah 'Test Kecerdasan'
Paham Pemikiran
Secara garis besar, AI terbagi ke dalam dua paham pemikiran yaitu AI Konvensional dan Kecerdasan Komputasional (CI, Computational Intelligence). AI konvensional kebanyakan melibatkan metode-metode yang sekarang diklasifiksikan sebagai pembelajaran mesin, yang ditandai dengan formalisme dan analisis statistik. Dikenal juga sebagai AI simbolis, AI logis, AI murni dan AI cara lama (GOFAI, Good Old Fashioned Artificial Intelligence). Metode-metodenya meliputi:
- Sistem pakar: menerapkan kapabilitas pertimbangan untuk mencapai kesimpulan. Sebuah sistem pakar dapat memproses sejumlah besar informasi yang diketahui dan menyediakan kesimpulan-kesimpulan berdasarkan pada informasi-informasi tersebut.
- Petimbangan berdasar kasus
- Jaringan Bayesian
- AI berdasar tingkah laku: metode modular pada pembentukan sistem AI secara manual
Kecerdasan komputasional melibatkan pengembangan atau pembelajaran iteratif (misalnya penalaan parameter seperti dalam sistem koneksionis. Pembelajaran ini berdasarkan pada data empiris dan diasosiasikan dengan AI non-simbolis, AI yang tak teratur dan perhitungan lunak. Metode-metode pokoknya meliputi:
- Jaringan Saraf: sistem dengan kemampuan pengenalan pola yang sangat kuat
- Logika kabur: teknik-teknik untuk pertimbangan di bawah ketidakpastian, telah digunakan secara meluas dalam industri modern dan sistem kendali produk konsumen.
- Komputasi Evolusioner: menerapkan konsep-konsep yang terinspirasi secara biologis seperti populasi, mutasi dan Sintasan yang paling layak untuk menghasilkan pemecahan masalah yang lebih baik.
Metode-metode ini terutama dibagi menjadi algoritme evolusioner (misalnya algoritme genetik) dan kecerdasan berkelompok (misalnya algoritme semut)
Dengan sistem cerdas hibrid, percobaan-percobaan dibuat untuk menggabungkan kedua kelompok ini. Aturan inferensi pakar dapat dibangkitkan melalui jaringan saraf atau aturan produksi dari pembelajaran statistik seperti dalam ACT-R. Sebuah pendekatan baru yang menjanjikan disebutkan bahwa penguatan kecerdasan mencoba untuk mencapai kecerdasan buatan dalam proses pengembangan evolusioner sebagai efek samping dari penguatan kecerdasan manusia melalui teknologi.
Sejarah kecerdasan buatan
Pada awal abad 17, René Descartes mengemukakan bahwa tubuh hewan bukanlah apa-apa melainkan hanya mesin-mesin yang rumit. Blaise Pascal menciptakan mesin penghitung digital mekanis pertama pada 1642. Pada 19, Charles Babbage dan Ada Lovelace bekerja pada mesin penghitung mekanis yang dapat diprogram.
Bertrand Russell dan Alfred North Whitehead menerbitkan Principia Mathematica, yang merombak logika formal. Warren McCulloch dan Walter Pitts menerbitkan "Kalkulus Logis Gagasan yang tetap ada dalam Aktivitas " pada 1943 yang meletakkan fondasi untuk jaringan saraf.
Tahun 1950-an adalah periode usaha aktif dalam AI. Program AI pertama yang bekerja ditulis pada 1951 untuk menjalankan mesin Ferranti Mark I di University of Manchester (UK): sebuah program permainan naskah yang ditulis oleh Christopher Strachey dan program permainan catur yang ditulis oleh Dietrich Prinz. John McCarthy membuat istilah "kecerdasan buatan " pada konferensi pertama yang disediakan untuk pokok persoalan ini, pada 1956. Dia juga menemukan bahasa pemrograman Lisp. Alan Turing memperkenalkan Uji Turing sebagai sebuah cara untuk mengoperasionalkan test perilaku cerdas. Joseph Weizenbaum membangun ELIZA, sebuah chatterbot yang menerapkan psikoterapi Rogerian.
Selama tahun 1960-an dan 1970-an, Joel Moses mendemonstrasikan kekuatan pertimbangan simbolis untuk mengintegrasikan masalah di dalam program Macsyma, program berbasis pengetahuan yang sukses pertama kali dalam bidang matematika. Marvin Minsky dan Seymour Papert menerbitkan Perceptrons, yang mendemostrasikan batas jaringan saraf sederhana dan Alain Colmerauer mengembangkan bahasa komputer Prolog. Ted Shortliffe mendemonstrasikan kekuatan sistem berbasis aturan untuk representasi pengetahuan dan inferensi dalam diagnosa dan terapi medis yang kadang kala disebut sebagai sistem pakar pertama. Hans Moravec mengembangkan kendaraan terkendali komputer pertama untuk mengatasi jalan berintang yang kusut secara mandiri.
Pada tahun 1980-an, jaringan saraf digunakan secara meluas dengan algoritme perambatan balik, pertama kali diterangkan oleh Paul John Werbos pada 1974. Pada tahun 1982, para ahli fisika seperti Hopfield menggunakan teknik-teknik statistika untuk menganalisis sifat-sifat penyimpanan dan optimasi pada jaringan saraf. Para ahli psikologi, David Rumelhart dan Geoff Hinton, melanjutkan penelitian mengenai model jaringan saraf pada memori. Pada tahun 1985-an sedikitnya empat kelompok riset menemukan kembali algoritme pembelajaran propagansi balik. Algoritme ini berhasil diimplementasikan ke dalam ilmu komputer dan psikologi. Tahun 1990-an ditandai perolehan besar dalam berbagai bidang AI dan demonstrasi berbagai macam aplikasi. Lebih khusus Deep Blue, sebuah komputer permainan catur, mengalahkan Garry Kasparov dalam sebuah pertandingan 6 game yang terkenal pada tahun 1997. DARPA menyatakan bahwa biaya yang disimpan melalui penerapan metode AI untuk unit penjadwalan dalam Perang Teluk pertama telah mengganti seluruh investasi dalam penelitian AI sejak tahun 1950 pada pemerintah AS.
Tantangan Hebat DARPA, yang dimulai pada 2004 dan berlanjut hingga hari ini, adalah sebuah pacuan untuk hadiah $2 juta dimana kendaraan dikemudikan sendiri tanpa komunikasi dengan manusia, menggunakan GPS, komputer dan susunan sensor yang canggih, melintasi beberapa ratus mil daerah gurun yang menantang.
Filosofi
Perdebatan tentang AI yang kuat dengan AI yang lemah masih menjadi topik hangat di antara filosof AI. Hal ini melibatkan filsafat budi dan masalah budi-tubuh. Roger Penrose dalam bukunya The Emperor's New Mind dan John Searle dengan eksperimen pemikiran "ruang China" berargumen bahwa kesadaran sejati tidak dapat dicapai oleh sistem logis formal, sementara Douglas Hofstadter dalam Gödel, Escher, Bach dan Daniel Dennett dalam Consciousness Explained memperlihatkan dukungannya atas fungsionalisme. Dalam pendapat banyak pendukung AI yang kuat, kesadaran buatan dianggap sebagai Cawan Suci kecerdasan buatan.
Fiksi sains
Dalam fiksi sains, AI umumnya dilukiskan sebagai kekuatan masa depan yang akan mencoba menggulingkan otoritas manusia seperti dalam HAL 9000, Skynet, Colossus and The Matrix atau sebagai penyerupaan manusia untuk memberikan layanan seperti C-3PO, Data, the Bicentennial Man, the Mechas dalam A.I. atau Sonny dalam I, Robot. Sifat dominasi dunia AI yang tak dapat dielakkan, kadang-kadang disebut "the Singularity", juga dibantah oleh beberapa penulis sains seperti Isaac Asimov, Vernor Vinge dan Kevin Warwick. Dalam pekerjaan seperti manga Ghost in the Shell-nya orang Jepang, keberadaan mesin cerdas mempersoalkan definisi hidup sebagai organisme lebih dari sekadar kategori entitas mandiri yang lebih luas, membangun konsep kecerdasan sistemik yang bergagasan.
Seri televisi BBC Blake's 7 menonjolkan sejumlah komputer cerdas, termasuk Zen (Blake's 7), komputer kontrol pesawat bintang Liberator (Blake's 7); Orac, superkomputer lanjut tingkat tinggi dalam kotak perspex portabel yang mempunyai kemampuan memikirkan dan bahkan memprediksikan masa depan; dan Slave, komputer pada pesawat bintang Scorpio.
Sumber Artikel: id.wikipedia.org
